The Cultural Significance of Timbre Analysis: A Case Study in 1980s Pop Music, Texture, and Narrative*
Megan L. Lavengood
KEYWORDS: Tina Turner, Level 42, Howard Jones, Janet Jackson, DX7, orchestration, functional layers, novelty layer, synthesizers, Band Aid
ABSTRACT: This article is in three interrelated parts. In Part 1, I present a methodology for analyzing timbre that combines spectrogram analysis and cultural analysis. I define a number of acoustic timbral attributes to which one may attune when analyzing timbre, organized as oppositional pairs of marked and unmarked terms, in order to both aid in spectrogram analysis and account for some of this cultural and perceptual work.
In Part 2, building from Allan Moore’s definition of four functional layers in pop texture, I argue for the adoption of a fifth layer, which I term the novelty layer. I study its construction in 1980s hit singles via the Yamaha DX7 synthesizer. The novelty layer is imbued with several layers of semiotic significance: it functions in opposition to the melodic layer, comprises instruments whose timbral characteristics are more resistant to blending with the rest of the ensemble, and often uses “world instruments” in 1980s popular music. This latter point is a reflection of the problematic treatment of world music by 1980s music culture. I use my approach to timbre analysis to define the timbral norms for the novelty layer as opposed to Moore’s other layers.
In Part 3, I create a dialogic narrative analysis of “Do They Know It’s Christmas?” by Band Aid (1984) that demonstrates what it might mean to transgress these norms. This analysis, in acknowledging the problematic cultural associations of the song, illustrates the rich discourse that can be produced when timbre is made central to the analytical process.
DOI: 10.30535/mto.26.3.3
Copyright © 2020 Society for Music Theory
Example 1. Prechorus and chorus of “What’s Love Got to Do with It” (0:36–0:57)

(click to enlarge and listen)
[0.1] Example 1 is a transcription of the prechorus and chorus of “What’s Love Got to Do with It” by Tina Turner, which reached #1 in the US in September 1984 and #3 in the UK in June 1984. To describe the texture of “What’s Love Got to Do with It,” the instruments can be understood using Allan Moore’s (2012) concept of four functional layers present in pop textures: the explicit beat layer, the functional bass layer, the melodic layer, and the harmonic filler layer. Tina Turner’s voice is the melody layer, which carries the main melody and lyrics.(1) The explicit beat layer and functional bass layer are found, as expected, in the drum set, which plays a basic rock beat, and in the bass line, which plays chord roots in slow, predictable rhythms before switching to a more linear bass in the reggae-tinged chorus, respectively. These two functional layers, according to Moore, work together to provide the “groove” of a pop song. The harmonic filler layer, which Moore defines as the layer whose function is “to fill the ‘registral’ space between [the functional bass and melody] layers,” is made up of the guitar, which plays strictly chordal accompanimental figures; one DX7 preset, E. PIANO 1, which, like the guitar, plays chordal accompaniment; and the strings, which thicken this core texture.
[0.2] Having exhausted Moore’s four functional layers, I have left one instrument uncategorized: the FLUTE 1 synthesizer sound. The musical content of this instrument is far less predictable than the other instruments, adding syncopated melodic interjections sporadically throughout the introduction. I suspect Moore would categorize this as belonging to the melody layer, and specifically as a “secondary melodic line” (2012, 20). But to me, this obscures the most interesting feature of the FLUTE 1 line: its distinct timbre, which sets it apart from the typical rock texture. How might an analyst acknowledge the way that timbre contributes to texture in this way?
[0.3] In this article, I present a methodology for analyzing timbre that combines spectrogram analysis and cultural analysis. To show how this methodology can be productively implemented, I expand Moore’s system by adding a fifth functional layer, which I term the novelty layer. Using my approach to timbre analysis, I find that the novelty layer is imbued with several layers of semiotic significance: it functions in opposition to the melodic layer, it comprises instruments whose timbral characteristics are more resistant to blending with the rest of the ensemble, and it is the most typical place to find “world instruments” in 1980s popular music. This allows me to construct a narrative through the analysis of timbre and texture.
[0.4] Spectrogram analysis first became popular among music theorists in the late 1970s, when computing became more accessible to academics. A smattering of books on timbre analysis using spectrograms was released between 1975 and 1985 (Erickson 1975; Cogan 1984; Slawson 1985), yet spectrogram analysis never became a mainstream analytical tool in music theory. One possible reason for this is what a spectrogram does not show: the significant role that perception plays in the experience of timbre, as articulated by Cornelia Fales in her foundational article “The Paradox of Timbre” (2002) and reinforced by the studies of other recent timbre scholars (Blake 2012; Heidemann 2014; Lavengood 2019).(2) I define a number of acoustic timbral attributes to which one may attune when analyzing timbre in order to both aid spectrogram analysis and account for some of this cultural and perceptual work. But identification of these attributes alone does not produce a stimulating analysis; this simply lays the groundwork for an engaging interpretation of a musical work.
[0.5] In order to more securely attach the spectrogram’s acoustic data to human experience, I have built my vocabulary for spectrogram analysis upon the notion of markedness, popularized in music studies by Robert Hatten (1994), as a way of analyzing the cultural associations that arise during the perceptual processing of timbral attributes. Put succinctly, markedness is the significance given to difference, often between two opposed terms. In Part 1, I will describe my methodology in detail, showing how spectrograms and consideration of markedness can aid analysts in creating timbre analyses. Part 1 is designed to establish a flexible theory for the analysis of timbre that could be applied to a wide range of repertoires and purposes, and thus the tools I describe there are not limited to those that would apply to the analyses in this article. In this sense, Part 1 almost functions as a manual or glossary for timbre analysis.
[0.6] My music analyses are in Parts 2 and 3 of this article. These two parts present analytical case studies that further develop Moore’s functional layers and my novelty layer as constructed in hit 1980s singles by the Yamaha DX7 synthesizer, an immensely popular synthesizer that helped define the sound of the 1980s. I ask readers to remember that Moore and I do not define functional layers by their timbral properties, but rather by the way the sounds are used in the track—that is, by their instrumentational role. Timbre and texture are not made equivalent in this essay, and the functional layers are descriptions of textural function rather than an assessment of timbral quality. However, by tracking the use of Yamaha DX7 presets in a number of mid-’80s hits and identifying their principal functional layers, I assess the levels of markedness within each layer to establish the timbral norms for each—norms which are particular to this idiom of 1980s mainstream popular music. I find that all DX7 presets used in the functional bass, melody, and harmonic filler layers have something in common: they have unmarked timbral characteristics that allow different instruments to blend into a texture. DX7 presets in the novelty layer, by contrast, have marked timbral features that encourage these instruments to stand out. In other words, I will show that in mainstream pop and rock music in the 1980s, the ideal for the instruments composing the former three layers (I refer to this combination as “core sounds” or “core layers”) is to blend with each other; for the novelty instruments, not to blend at all.
[0.7] Part 3 concludes the article by using timbral norms to create a dialogic narrative analysis of “Do They Know It’s Christmas?” by Band Aid (1984) as an example of what it might mean to transgress the timbral norms established in Part 2. This analysis, in acknowledging the problematic cultural associations of the song, illustrates the rich discourse that can be produced when timbre is made central to the analytical process.
1. Methodology for Visual Spectrogram Analysis
Video Example 1. A spectrogram
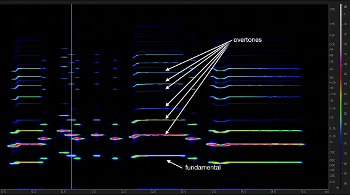
(click to watch video)
[1.1] With free software such as Audacity or Sonic Visualiser, anyone with access to a computer may easily view a kind of visual transcription of the timbre of any recorded sound.(3) A spectrogram charts frequency on the y-axis and time on the x-axis, while showing amplitude with changes in color as a type of z-axis (Video Example 1). This visualizes in three dimensions the relative weighting of the energy distribution within a given frequency range and provides a visual representation of most of the elements that define a timbre.(4) Put another way, a spectrogram shows the amplitude of all the frequencies present in a sound signal and the way those amplitudes and frequencies change through time. This spectrogram shows not only the fundamental pitch, but also all the overtones that the ear combines into a single tone with a unique timbre.
Example 2. A spectrum plot showing a single moment of time
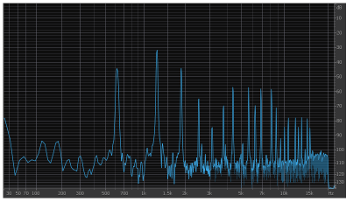
(click to enlarge)
[1.2] Another visual representation of timbre is called a spectrum plot (Example 2). In a spectrum plot, frequency is charted on the x-axis and amplitude on the y-axis, which provide two advantages over spectrograms: one, they are easier to read when showing a single moment of time, and two, they are useful for calculating exact differences in amplitude between various partials. The drawback is that spectrum plots do not show changes in timbre through time.(5) I detail some situations in which spectrum plots are particularly helpful when I define my oppositions.
[1.3] Spectrograms may at first appear to have an overwhelming amount of information, so I have built into my methodology a vocabulary for describing timbral attributes that are visible in spectrograms, grounded in a system of binary oppositions. In sum, I have ten total oppositions, grouped into three categories: 1) spectral components of the sustain (steady state) portion of the sound, 2) spectral components of the attack (onset) portion of the sound, and 3) pitch components.(6) In this way, I borrow from Robert Cogan’s pioneering research in his book New Images of Musical Sound (1984).(7) In other ways, I depart from Cogan’s methodology. Smaller changes include my addition of new oppositions that pay special attention to the analysis of onsets or attack points of sounds, and my omission of some oppositions that I have not found to be useful. The most significant development I make is to repurpose Cogan’s system of binaries to address the concept of musical markedness, rather than his notion of spectral energy.(8) Taking note of markedness allows for a succinct explanation of which timbral attributes are normative and which are non-normative.
[1.4] Many binary oppositions are asymmetrical, meaning that one term carries more weight in terms of perception, cultural meaning, and so forth; following Robert Hatten (1994), I will refer to this weightier term as the marked term.(9) As a linguistic example, Hatten cites man / woman: woman is marked and man is unmarked, because the term “man” can (still) be used to describe a generic person of any gender (“snowman,” “no man’s land”), while “woman” necessarily describes female-gendered people (a “snowwoman” would be explicitly female, while a “snowman” could be seen as genderless). Note, significantly, that markedness does not necessarily correlate to prevalence, as men and women are nearly equally prevalent in the world, yet woman is the marked term. Classical music provides many situations that create musical markedness: a four-bar phrase would be unmarked, whereas a five-bar phrase would be marked as having special significance (Hatten 1994, 34–36). Incorporating markedness into the analysis of timbre via spectrograms not only liaises between acoustics and listener experience, but also imbues the analysis with a sense of cultural attention and nuance.
[1.5] Context remains paramount here, as the analyst must determine which sounds are marked and unmarked based on the particular cultural situation surrounding the sound signal in question. Throughout this article, I analyze 1980s popular music, and specifically, the Yamaha DX7 FM digital synthesizer. My focus on this synthesizer may seem overly niche or specialized, but many people already know this instrument by sound if not by name. As I have shown in another study (Lavengood 2019), the electric piano preset (E. PIANO 1) was particularly commonplace in late-1980s pop music; even professionally produced songs typically used the DX7’s factory preset sounds instead of creating new sounds from scratch. This means I can aurally recognize the preset sounds used on a track, record the musical line using the preset from my personal DX7, and have clean samples of practically the same timbres as the ones on the track.(10) This facilitates my analyses, because my methodology tends to work better when each voice can be isolated, while composite and heterogenous textures often obscure important details in spectrograms. The presets were so popular that, even though the DX7 was produced for only a few years, Yamaha sold around 150,000 of them; the DX7 is still today one of the best-selling synthesizers of all time.(11) Its popularity not only helps justify my study of the synthesizer, but also ensures that I have a large body of music from a variety of genres available to study.
[1.6] Returning to the notion of markedness, I have assigned positive and negative signs to the oppositions in my methodology to reflect markedness within this particular cultural context. To do this, I compare DX7 sounds to what I consider the prototypical pop music sound: the clean electric guitar sound. The guitar has been the primary instrument of popular music from the 1950s (if not earlier) to the 2000s in almost every genre. I choose an undistorted guitar sound over a distorted sound because any addition of distortion or other effects narrows the generic and expressive range of the guitar considerably. Comparing the use of major and minor modes in the Classical era, Hatten (1994) considers minor as marked because minor keys would express the tragic; major keys might convey the direct opposite (the comic), but they might also convey a large number of other meanings, such as pastoral, military, and so on. Guitar distortion does the same kind of work on genres within popular music: the distorted guitar signifies a narrower range of genres than the more flexible undistorted sound. Guitar distortion might narrow the genre from the umbrella category of “popular music” down to “rock music.” Certain kinds of distortion might narrow it still further to “heavy metal.” An undistorted, clean guitar sound, by contrast, has a wider range of signifying possibilities for genre and expression. Consider the electric guitar sounds used by a mainstream pop artist like Madonna: the guitar timbres are generally clean unless the specific tropes associated with distorted guitars are invoked. For example, the opening of “Like a Prayer,” which has a brief distorted guitar riff that gets interrupted by the slamming of a church door, uses electric guitar as a timbral representative of the secular, which is immediately contrasted with the sacred’s representative timbre, the church organ and choir.(12) Again, the most important consideration in determining markedness is context. For my work in this article, I am taking pop music of 1950–1990 as my context. If one were to analyze a narrower range of genres or a different context, what is marked and what is unmarked would change. Within the context of metal, for example, the reverse of my proposition would be true: clean guitar would be marked, and distorted unmarked. I am asserting that the clean electric guitar is a signifier for that broadest category of all recorded rock music prior to 1990.
[1.7] Each time I analyze another sound in terms of these positive or negative attributes, I am assessing whether the element signifies (is marked) or whether it is essentially generic and thus non-signifying. By comparing the sound to the clean electric guitar as an aural symbol of mainstream popular music, with each positive or negative sign, I am making a statement about the degree to which a given signal conforms to the norms of pop music, as represented by the clean electric guitar. This has profound implications in the following narrative analyses, where I make connections between timbre, markedness, texture, and instrumentation.
Video Example 2. Spectrogram of a “clean” electric guitar sound
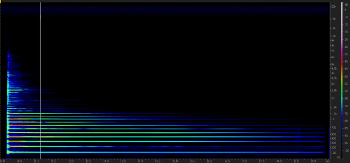
(click to watch video)
[1.8] As my sample and reference point for a clean electric guitar sound, I use the sound signal from Movie Example 5(a) of Ciro Scotto’s 2017 article on guitar distortion.(13) I analyzed this sound considering each of the oppositions given above and used the results to determine which oppositional term would be unmarked (negative): whichever term applied to the clean electric guitar became the negative or unmarked oppositional term. In what follows, therefore, the timbre of the clean electric guitar is represented by each of the terms on the left of the slash in the oppositional pairings: bright, pure, full, rich, beatless, harmonic, percussive, bright (attack), steady (Video Example 2), terms which I define further below.(14) For the timbral attributes that are spectral components, I provide video examples in the form of a spectrogram that puts two opposing sound signals (each a Yamaha DX7 synthesizer preset sound) side-by-side for comparison. I have annotated all the spectrograms in white. Here and throughout my article, oppositional terminology is given in italics.
Spectral components of the sustain
Video Example 3. CLAV 1 (left) and FLUTE 1 (right) exmplifying bright / dark and pure / noisy

(click to watch video)
[1.9] Bright / dark. This opposition is based on spectral centroid measurements, which might be understood as the center of the distributed energy in a sound sample. Spectral centroids are given as a value in Hz, which represents the midpoint of the frequency range weighted by amplitude. Whether this value converts to bright or dark is a contextual decision, left to the analyst; my own decision for this article is to consider anything above 1100 Hz bright and anything below dark.(15) The spectral centroid must be calculated with a music information retrieval (MIR) tool. This opposition is the only one not deducible from visual analysis of the spectrogram; to compensate for this, I have manually annotated my spectrograms in this article with dotted lines that indicate the approximate position of the centroid.(16) The dotted lines drawn on Video Example 3 illustrate the two centroids for these two samples. Because the left centroid is above 1100 Hz, it is bright in this analysis; the right centroid is below that threshold and is dark.
[1.10] Pure / noisy. This opposition considers the thickness of the bands of each spectral element; that is, the breadth of the energy distribution across the spectrum. On the spectrogram, sounds that are pure have thin strands for their spectral elements; sounds that are noisy have thicker bands, or perhaps a strand that is surrounded by a halo of lower-amplitude energy (Video Example 3). The thicker the band, the noisier the sound. On the extremes, the resonant tone of a struck vibraphone would produce a very pure sound, while a snare drum would produce a very noisy sound.
Video Example 4. CLAV 1 (left) and CLARINET (right) exemplifying full / hollow
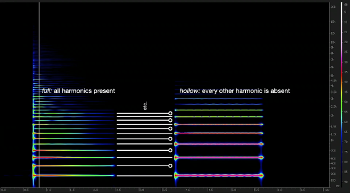
(click to watch video)
[1.11] Full / hollow. Some instruments do not sound all of the harmonics in the harmonic series when playing (perhaps most famously the clarinet, which omits the even-numbered overtones). Any sound that does not sound all the harmonics would be an example of a hollow sound; a full sound uses all harmonics.(17) On the spectrogram, a hollow sound will appear to have more space between each of its partials (Video Example 4). Some sound signals may be hollow even when all the overtones are sounded if some of the overtones are considerably louder than others. Typically, the fundamental is the loudest partial in a sound, and the amplitude of subsequent partials decreases in a regular pattern. If instead every other partial is louder than the ones in between, the sound may be hollow. In such an instance, one might think of the partials as being imbalanced. Using a spectrum plot rather than a spectrogram may help identify whether or not any partials are absent or under-emphasized.
Video Example 5. CLAV 1 (left) and MARIMBA (right) exemplifying rich / sparse

(click to watch video)
[1.12] Rich / sparse. This attunes to the number of partials present in a given sonority, without reference to the harmonic series. A sound with many partials is rich, while one with few is sparse (Video Example 5). For sounds that do not have discernible partials, a sound that has wider bands is more rich than a sound with narrower bands. Cogan (1984, 136–7) gives the example of a sine wave, which would appear on the spectrogram as a single strand, as the most sparse sound; he gives white noise, which appears on the spectrogram as a solid mass taking up the entire frequency range, as the richest sound.
Video Example 6. CLAV 1 (left) and E. PIANO 1 (right) exemplifying beatless / beating
(click to watch video)
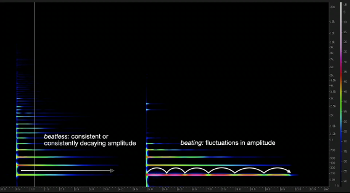
[1.13] Beatless / beating. This refers to the presence or absence of acoustic beats, also known as sensory dissonance (Helmholtz 1875, 247) or auditory roughness (Sethares 2005). Beats occur between two frequencies that are very close in range, resulting in interference between the two sound waves. This manifests aurally as regular fluctuations in loudness called “beats.” On the spectrogram, this will appear as a periodic brightening and darkening of the shade used to render the partial (Video Example 6).
Video Example 7. CLAV 1 (left) and TOY PIANO (right) exemplifying harmonic / inharmonic
(click to watch video)
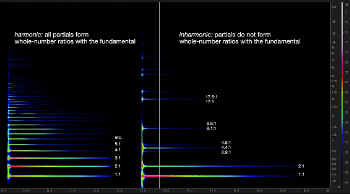
[1.14] Harmonic / inharmonic. A sound that is harmonic contains partials whose frequencies are strictly in whole-number ratios with the fundamental frequency—in other words, its partials are true harmonics.(18) In Video Example 7, the sound on the left is harmonic: its fundamental is at 176 Hz, the partial above that is 353 Hz (a 2:1 ratio with the fundamental), the following partial above that is 529 Hz (a 3:1 ratio), and so on all the way up its overtone series. A sound that is inharmonic has some partials not in whole-number ratios to the fundamental. The sound on the left of Video Example 7 also has a fundamental of 176 Hz, and its second partial is 356 (effectively a 2:1 ratio), but its third partial of a similar loudness is 697 Hz, which is a 4.45:1 ratio. Bells are perhaps the most well-known examples of sounds with inharmonic partials, caused by the stiffness of the vibrating bodies in each. Visually, inharmonic partials are most easily identified on a spectrogram when they appear in particularly tight clusters. As with hollowness, using a spectrum plot rather than a spectrogram may help identify inharmonic partials.
Spectral components of the attack
Video Example 8. CLAV 1 (left) and VOICE 1 (right) exemplifying percussive / legato, bright / dark (attack), and steady / wavering
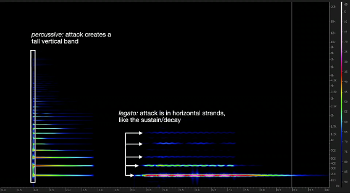
(click to watch video)
[1.15] Percussive / legato. This opposition is the same as pure / noisy (see above) in the spectral components of the sustain, but instead considers only the attack or the onset of the sound signal. I have changed the words to reflect a change in orientation to the attack portion of the sound. A noisy or percussive attack has a wide band of energy at the attack, such as would be produced by a glottal onset in singing or a forceful strike of a piano key; a pure or legato attack has a narrow band of sound at the attack, such as would be produced by a coordinated or aspirated onset in singing or an air attack in the clarinet (Video Example 8).
[1.16] Bright / dark. Again, this consideration is the same as bright / dark above, but now applies to the attack portion of the sound rather than the sustain (Video Example 8).
[1.17] Older approaches to spectrogram analysis tend to focus on the decay or sustain portions of a sound, also known as the steady state. Because of this, my oppositions for the sustain portion of the sound will be familiar to many readers. The attack of a sound also contributes a great deal to the perception of its timbre.(19) Without a separate attack profile, listeners typically categorize sounds as particularly synthesized or robotic, likely because almost all acoustic instruments have an attack profile that differs from their sustained tone. An attack sound can also vary in many ways. For example, the attack of a piano sound when the hammer strikes the string is not the same as the attack of a harpsichord sound when the plectrum plucks the string, and both of these sound nothing like the attack of a trumpet note. Studies like Saldanha and Corso 1964 show that the attack of a sound plays a large role in a listener’s ability to accurately determine the sound’s source.(20) This significant aspect of timbre must not be reduced to something as basic as the presence or absence of a separate attack profile.
Pitch components
[1.18] Low / high. This describes the position in pitch space of the sound signal. While this may not be a strictly timbral attribute, the frequency of the fundamental impacts timbre perception. For example, high sounds may sound bright even when the distance between their fundamentals and highest partials is not particularly wide because a high-pitched tone inherently possesses more high-frequency energy.(21) Therefore, this pitch attribute is relevant to an analysis of timbre.
[1.19] Steady / wavering. A sound is wavering if there are micro-fluctuations in the frequency of the sound signal, as in vibrato. Otherwise, it is steady. The difference is clear in the spectrogram, where a wavy line corresponds to a wavering sound and a straight line to a steady sound (Video Example 8). Again, this has to do primarily with frequency (pitch), but vibrato is widely considered by musicians to be an aspect of timbre nonetheless.
[1.20] These sound properties that I have categorized as “pitch components” may not seem to be timbral attributes if timbre is defined in a more conservative sense, as in the common “negative” definition (for example, “parameters of perception that are not accounted for by pitch, loudness, spatial position, duration, and various environmental characteristics” [McAdams and Giordano 2008]). But I am concerned less with the boundaries of timbre than with approximating the experience of timbre through my analysis. I consider pitch and dynamics in my spectrogram analyses because listeners experience timbre in a holistic way that does not easily discern a pitch attribute from a timbre attribute. Harcus (2017) theorizes at length on the interconnectivity of several domains of music that meld in the perception of musical objects—what he terms the “totality of involvements.” Harcus’s example of the differences between minor sevenths in different contexts (blues vs. Classical) provides a useful analogy for my understanding of timbre. While one might locate the differences between these minor sevenths not in the interval itself, but in the interval’s function, Harcus argues instead that these things are perceptually inseparable (2017, 61–63). The domains that contribute to timbre perception are similarly difficult, or even futile, to tease out.
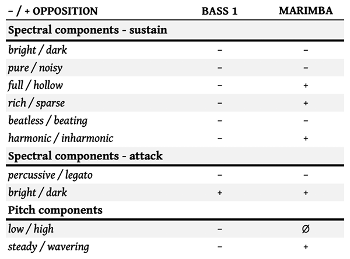
Example 3. An opposition table comparing two sounds
(click to enlarge)
[1.21] One can analyze a spectrogram by going through this list of oppositions and determining which of the two terms better suits the sound. As a shorthand, the negative sign (−) can be used for the term on the left of the slash, and the positive sign (+) can signify the term on the right. Terms are on the left or the right of the slash based on whether or not they are “marked” terms. Occasionally, a signal might exhibit the negative property at some times and the positive property at other times; in these cases, the analyst can use the mixed label (±) to indicate the presence of both timbral attributes. The null sign (∅) can likewise be used when the sound exhibits neither property. These designations can then be summarized in an opposition table, which the analyst can use to easily compare different sound signals (Example 3).
[1.22] Reducing timbral properties to a binary opposition may seem overly crude, as Hardman 2020 aptly argues. Many aspects of music occur on a gradual scale rather than a simple on/off system, and this is true for timbre as well. On most synthesizers, for example, the attack time of a sound can be adjusted by the programmer over a theoretically infinite range of values between zero (the fastest attack) and its maximum number (the slowest attack). Yet I am proposing that the speed of attack is analyzable with a simple binary: percussive / legato. While the reader might view this as an oversimplification, binaries prove an effective starting point for discussion as long as those binaries are contextually, not rigidly, defined.(22)
[1.23] Tracking and quantifying timbral attributes through oppositions is a useful entry point for timbre analysis, yet marking positive and negative signs in a table does little to enhance our understanding of how timbre interacts with other domains of music as they unfold in time. In this sense, the process of defining timbres through oppositions is somewhat like the process of assigning Roman numerals to harmonies in a piece of Classical music. An analyst must do this to begin analyzing harmony, but the Roman numerals (like oppositions) on their own are probably not particularly compelling for someone reading the analysis. One must find a way of meaningfully interpreting the raw data of the opposition tables. There are a multitude of possibilities for such interpretation: for example, the definition of a relationship between timbre and formal function, as in the work of Jean-Charles François (1991) regarding the music of Edgar Varèse; the relationship between timbre and identity as in the work of Blake (2012) and Heidemann (2016); and the relationship between timbre and embodiment as in the work of Heidemann (2016) and Wallmark (2018).
[1.24] Exactly what form this interpretation takes is ultimately up to the analyst, but the common thread binding these compelling studies is the identification of some kind of function of timbre—be it formal function, social function, or some other kind. The linguists from whom Cogan borrowed liberally—Saussure, Jakobson, Waugh, and others—always return to the function of phonemes within a larger context of language as a whole whenever they analyze phonemes as sound. In language, an understanding of function is perhaps more explicitly needed; according to these structuralists, what is the point of studying a language—that is, a tool for communication—if communication is left unaddressed? Music may not be a language, but in its own sense, it does communicate; thus, without notions of function, signification, or meaning, the bits of data are meaningless. With this in mind, I show in the following sections that certain timbral attributes function to reinforce norms of texture: unmarked attributes correspond to Moore’s four functional layers, while marked attributes correspond to my novelty layer.
2. Norms of Timbre, Texture, and Instrumentation in 1980s Pop Music
[2.1] In this section and the next, I address timbre, texture, and instrumentation in 1980s synth pop music, focusing especially on the role that the notion of blend plays in texture.(23) I analyze DX7 presets as they are used in several synth pop hit singles produced during 1983–87, at the height of the DX7’s popularity in commercial music. My first step in these analyses is to define the functional layer that each DX7 preset belongs to. I remind the reader that my determinations of function here do not rely on timbre analysis. Identifying functional layers involves merely separating lines into functional bass, melodic, explicit beat, harmonic filler, and novelty layers.
[2.2] Once I have described the texture of each example, I use the methodology I established in Part 1 to describe the timbre of the various Yamaha DX7 synthesizer presets. This analysis allows me to define timbral norms for the novelty layer as well as other layers. These timbral norms are emergent properties of the layers; they do not define the layers a priori. The timbral norms merely reflect listener expectations for typical versus atypical use of a given DX7 preset.
[2.3] Establishing these norms prepares the analysis in Part 3: the creation of narrative trajectories and musical meaning created through the transgression or reversal of the norms, which is the organizing force behind my analysis of “Do They Know It’s Christmas.” In addition to providing an account of timbre, texture, and instrumentation in 1980s mainstream popular music, I also demonstrate the versatility of my approach to timbre analysis.
Example 4. Instrumental break of “What’s Love Got to Do with It” (1:57–2:10)

(click to enlarge and listen)
[2.4] “What’s Love Got to Do with It” is a particularly good introductory example, as it is one of the earliest recorded singles to use the Yamaha DX7 and uses four presets: FLUTE 1 and E. PIANO 1, as I discussed in the introduction, as well as CALIOPE (misspelled as such in the internal memory, and often colloquially referred to as a “pan flute” preset) and HARMONICA. HARMONICA first appears in a lengthy solo section during the instrumental break (Example 4). Here, HARMONICA is part of the melodic layer. It functions as a replacement for Turner’s voice, providing a little timbral contrast in this solo section. After this instrumental concludes and after the bridge, the HARMONICA returns during the final choruses of the track, providing improvised descant lines simultaneously with Turner’s vocals, much like a duetting singer.
Example 5. Introduction of “What’s Love Got to Do with It” (0:00–0:08)

(click to enlarge and listen)
[2.5] CALIOPE is used in the introduction of the track (Example 5). CALIOPE, like FLUTE 1 described at the outset of this article, creates the novelty layer. The novelty layer is related to the melodic layer since it also contains essentially melodic (rather than harmonic) pitch content, yet it serves a different function than the melody, or may even be in opposition with the melody—a call-and-response musical dialog between melody and novelty layers is common. Whereas the melody layer is an integral part of nearly every popular song, a novelty layer is not essential.
[2.6] The novelty layer has been recognized by other names in several other cultural and historical contexts which also distinguish them from the melody layer.(24) Bobby Owsinski’s Mixing Engineer’s Handbook (2013) names five “arrangement elements”: the foundation, pad, rhythm, lead, and fills. What Owsinski calls “lead” is analogous to Moore’s melodic layer; what he calls “fills” is my novelty layer. Organists may also find the distinction familiar from discussions of stops. Melody-layer sounds are referred to as “solo” stops, while novelty-layer sounds are sometimes called “toy stops.”(25) Toy stops include things like zimbelstern (a stop that begins a perpetual tinkling of bells), chimes, pauke (timpani), and other such unusual and non-organ-like sounds whose usage would be reserved only for special occasions like Christmas and Easter. Even in early music, the distinction can be found. Agostino Agazzari, writing in 1607 about playing in a consort or large ensemble, spoke of instruments that are “like ornaments” versus those that are “like a foundation”; the former instruments are novelty-layer sounds.(26) Ornamental instruments, in Agazzari’s view, serve “no other purpose than to ornament and beautify, and indeed to season the consort” ([1607] 1998, 117). Agazzari’s use of the word “season” (Italian: condire) has a peculiar resonance with the word “sweeten”—“sweeteners” is a term commonly used by sound designers for the kinds of finishing touches a novelty sound might provide. Of these terms, I have chosen “novelty” to describe this functional layer because it evokes a sense of deploying unusual timbres for their titillating effects, and connotes the culturally appropriative manner in which these sounds were often deployed.
[2.7] Novelty layers are found outside of 1980s music as well. A well-known early example would be the piccolo trumpet in “Penny Lane” (1967) by The Beatles, where it has a limited role, only sounding intermittently as one of the track’s hooks. The novelty layer is used sparingly for coloristic effects, and is typically featured in intros, outros, and interludes. Other familiar examples include the brass in “Sussudio” (1985) by Phil Collins, the tin whistle prominently featured in “My Heart Will Go On” (1997) by Celine Dion, or the alto saxophone riff in the chorus of “Talk Dirty (to Me)” (2013) by Jason Derulo. In the latter two cases, both novelty instruments also have a particular “world music” connotation, the tin whistle signifying the lower-class and often Irish workers on board the Titanic, and the alto saxophone representing a genericized Arabic orientalism, accentuated by the prominent augmented second in the riff that recalls the hijaz maqam.
[2.8] Several of the most remarkable and well-known Yamaha DX7 presets are other such “world music” sounds that are likewise typically used in the novelty layer, such as the STEEL DRM, MARIMBA, KOTO, and CALIOPE. That these presets often mimic folk instruments from the Global South is deserving of further comment, as their deployment within the novelty layer seems to marginalize them further by using them for exotic appeal. Theo Cateforis (2011) asserts that appropriational musical crossover from non-Western musics was integral to new wave music (the early-1980s genre out of which synth pop more broadly grew) and to the 1980s music scene as a whole. To make this argument, he discusses the Adam and the Ants album Kings of the Wild Frontier (1980), the Talking Heads album Remain in Light (1980), and the pervasiveness of the “Burundi Beat” in the music of many artists. It was in the 1980s that the genres of “world music” and “world beat” were popularized and mainstream. Other examples of this phenomenon discussed by scholars include Steven Feld’s “Notes on World Beat” (1988), which critiques the power dynamics in Paul Simon’s use of South African musicians and styles in Graceland (1986), as well as Louise Meintjes’s book Sound of Africa! (2003), which documents the use of South African musics as representatives of Africanness in popular music. In short, a nascent interest in globalism within 1980s music culture, while motivated in part by an interest in diversity, resulted in the blurring together of elements of non-Western music that, within their original contexts, would ordinarily be highly differentiated. I understand the use of “world music” DX7 presets within novelty layers to be emblematic of this sort of colonialist appropriation.
[2.9] CALIOPE resembles the sound of the pan flute, an instrument often associated with indigenous cultures of the Andean mountain region; given the lyrical themes of no-strings-attached eroticism in “What’s Love Got to Do With It,” for me, the use of CALIOPE in this context is evocative of the “Sexualized [Native] Maiden” trope common to Western media.(27) Example 5 shows CALIOPE interjecting with syncopated motives throughout the introduction, setting the scene for the entire track with this vaguely Native atmosphere.
Example 6. Opposition table for “What’s Love Got to Do with It”
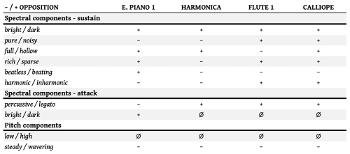
(click to enlarge)
[2.10] Video Examples 9–12 are spectrograms for the presets used in “What’s Love Got to Do with It.” These spectrograms and their timbral attributes are summarized in the opposition table given in Example 6.(28) The opposition table helps connect the assessment of each sound’s functional layer to each sound’s timbre. The functional layers are not defined through timbre—functional layers are a purely textural concern—yet there are correlations between these two concepts. Focusing on the rows that show variation from preset to preset, there are two attributes FLUTE 1 and CALIOPE share with each other and not with E. PIANO 1 or HARMONICA: noisy and inharmonic. E. PIANO 1 and HARMONICA are pure and harmonic presets. Recalling that the assignment of positives and negatives correlates to markedness and unmarkedness, respectively, note that the FLUTE 1 and CALIOPE presets are both in the novelty layer, and they both have the marked timbral properties (noisy and inharmonic). Compare this to E. PIANO 1 as a part of the harmonic filler layer and HARMONICA as the melodic layer. These two layers have deeper roots in pop and rock music, and similarly, E. PIANO 1 and HARMONICA both have unmarked properties (pure and harmonic). These groupings reinforce each other: timbral attributes align with the functional layers of these presets. This reflects Hatten’s principle of markedness assimilation: marked entities are typically found in marked contexts. FLUTE 1 and CALIOPE are timbrally marked as I described, they are rhythmically marked through their syncopated entries, they are present in a marked functional layer, and they are culturally marked as instruments that are non-standard for this style of music. Examining additional tracks using DX7 presets can help further solidify the timbral norms of various functional layers.
Video Example 9. E. PIANO 1 as heard in Example 4
(click to watch video) | Video Example 10. HARMONICA as heard in Example 4
(click to watch video) |

Video Example 11. FLUTE 1 as heard in Example 1
(click to watch video) | Video Example 12. CALIOPE as heard in Example 5
(click to watch video) |

[2.11] “What Is Love?,” the second single released from the debut album Human’s Lib by British synthpop artist Howard Jones, peaked at #2 in the UK in November 1983 and at #33 in the US the following June. Jones was another of the earliest adopters of the Yamaha DX7, and Human’s Lib, recorded in late 1983, makes extensive use of this new technology. “What Is Love?” is saturated with the presets of the DX7, featuring four factory presets: BASS 1, BRASS 2, TUB BELLS, and CALIOPE. Example 7 is a transcription of the introduction of this track, using three of these presets. The BASS 1 preset is the functional bass layer; CALIOPE and TUB BELLS make up the novelty layer. I still hear the CALIOPE as an aural token for Nativeness, but the atmospheric wash of sound that contextualizes it evokes more of a generalized sense of mysticism often associated with Native American peoples. This sense of mysticism is strengthened for me by the use of TUB BELLS, as the sound is reminiscent of church bells. BRASS 2 is first heard in the second verse of the track (Example 8). Here, BRASS 2 is in the melodic layer. It joins with and bolsters Jones’s voice, work that traditionally would be done by double-tracking the vocals. BRASS 2 takes on the role of the voice and thus is a melody instrument.
Example 7. Introduction of “What Is Love?” (0:00–0:20)
(click to enlarge and listen) | Example 8. Verse 2 of “What Is Love?” (1:07–1:17)
(click to enlarge and listen) |


Example 9. Opposition table for the sounds used in “What Is Love”
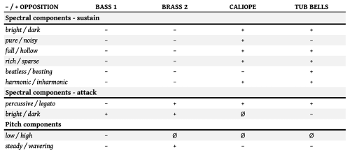
(click to enlarge)
[2.12] Video Examples 13–16 are the spectrogram images for the DX7 presets used in this track. Example 9 is the opposition table for these four presets.(29) The two novelty-layer sounds, TUB BELLS and CALIOPE, share a number of timbral features with each other that BASS 1 and BRASS 2 do not have. BASS 1 and BRASS 2 are both harmonic, full, and rich sounds, whereas TUB BELLS and CALIOPE are inharmonic, hollow, and sparse. Again, like in “What’s Love Got to Do with It,” the properties that BASS 1 and BRASS 2 share (harmonic, full, rich) are all unmarked designations within the opposition, and the properties CALIOPE and TUB BELLS share are all positive (inharmonic, hollow, sparse). In sum, TUB BELLS and CALIOPE are more marked than BASS 1 and BRASS 2. Once again, the groupings according to textural function and the groupings according to timbre reinforce each other.
Video Example 13. BASS 1 as shown in Example 7
(click to watch video) | Video Example 14. BRASS 2 as shown in Example 8
(click to watch video) |

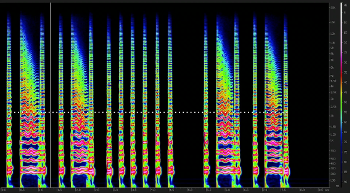
Video Example 15. CALIOPE as shown in Example 7
(click to watch video) | Video Example 16. TUB BELLS as shown in Example 7
(click to watch video) |
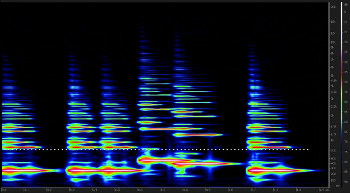

[2.13] Even in 1987, the DX7 was still abundant in pop music. Jazz-funk band Level 42 made extensive use of DX7 presets in their 1987 album, Running in the Family. The official video for the title track shows synth player Mike Lindup using two DX7s stacked on top of each other to play all the lines in the track. This track peaked at #6 in the UK in February 1987, though it only climbed to #83 in the US in August. The sounds used include CLAV 1, E. PIANO 1, and VIBES, all of which are used at once in Verse 2 of “Running in the Family” (Example 10).
[2.14] Each one of these DX7 sounds has a different textural function. Like BRASS 2 in “What Is Love?,” CLAV 1 bolsters Mark King’s lead vocals in the verses of “Running in the Family” and so functions as part of the melodic layer. CLAV 1 is an extremely bright and rich sound, visible and audible in the spectrogram (Video Example 17).(30) E. PIANO is in the harmonic filler layer, functioning (as it almost always does) as a harmonic pad, as in the Tina Turner example. Video Example 18 is the spectrogram for E. PIANO 1. VIBES makes up the novelty later, interjecting improvisatory flurries of notes in a call-and-response with the melodic layer. The spectrogram demonstrates that the VIBES preset is hollow, sparse, and dark (Video Example 19).(31) The functional layers in “Running in the Family,” in short, have marked and unmarked timbral attributes similar to the presets used in “What Is Love?” and “What’s Love Got to Do with It.”
Example 10. Verse 2 of “Running in the Family” (1:46–1:57)
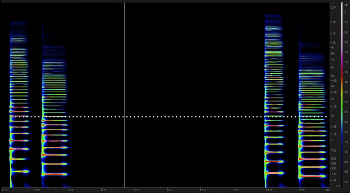
(click to watch video) | Video Example 17. CLAV 1 as shown in Example 10
(click to enlarge) |

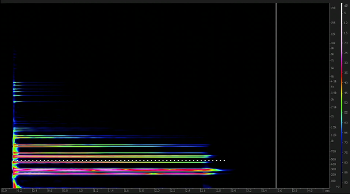
Video Example 18. E PIANO 1 as shown in Example 10
(click to watch video) | Video Example 19. VIBES as shown in Example 10
(click to watch video) |
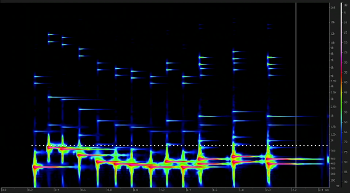
Example 11. Formal diagram for “When I Think of You”

(click to enlarge and listen)
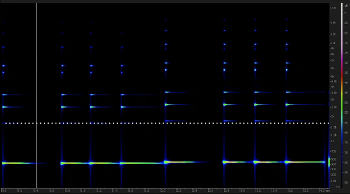
Video Example 20. MARIMBA preset in “When I Think of You”
(click to watch video)
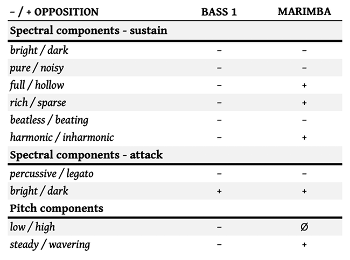
Example 12. Opposition table for the presets used in “When I Think of You”
(click to enlarge)
[2.15] Janet Jackson’s “When I Think of You” from her album Control reached #1 in the US in October 1986 and #10 in the UK two months prior. This track uses MARIMBA as its novelty layer, introducing a rhythmic motive above the electric piano (surprisingly, not a DX7 electric piano) in the verses and postchoruses. BASS 1 is the functional bass layer, to which Jackson draws attention by announcing “Bass!” before a lengthy bass feature. The form of this single is unconventional for mainstream popular music (Example 11). The intro and bridge of this track are both disproportionately long compared to other pop/rock singles, and the music after the bridge does not comprise the typical repetitions of the chorus, but rather a repeat of the postchorus, a breakdown, and an outro, which could be understood together as an extended outro, lasting from 3:03 until 3:55.
[2.16] Video Example 20 is a spectrogram for the MARIMBA preset, and Example 12 is the opposition table.(32) The preset is hollow, sparse, wavering, and inharmonic, several attributes that help the preset stand out against the busy groove. The fact that the MARIMBA has very little sustain and a quick decay makes it particularly suitable in short, punchy rhythms. The MARIMBA is mostly restricted to this role until the breakdown section, where the MARIMBA takes on the role the electric guitar had earlier in the introduction. Out of context, MARIMBA may sound like part of the harmonic filler layer here because it persists through so much of the track. But taking a broader view of the breakdown as one section of an extended outro (as suggested before), MARIMBA still comes across as a novelty sound, one that is featured in the breakdown.
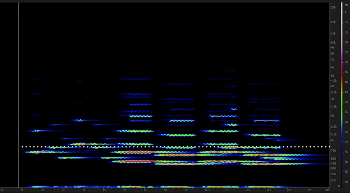
Video Example 21. VOICE 1 as shown in Example 16
(click to enlarge)
[2.17] Thus far I have mentioned the use of the following ten DX7 presets: BASS 1, E. PIANO 1, TUB BELLS, CALIOPE, FLUTE 1, MARIMBA, VIBES, BRASS 2, HARMONICA, and CLAV 1. I’ll briefly discuss a preset that will be used in the following discussion of “Do They Know It’s Christmas?”: VOICE 1. Video Example 21 is the spectrogram of the VOICE 1 preset as featured in the lead-in to the bridge. This sound has an extremely legato attack—the note gradually increases in volume, and overtones are gradually added in as the note is sustained. VOICE 1 is a rich preset with many overtones, but only after the notes have sounded for some time, since overtones are layered in throughout the sustain. Rather than being loudest at the beginning of the note, as is normal for most of the DX7 timbres, peak volume occurs rather far into the sustain—almost half a second in.
[2.18] Having now looked at a number of ’80s songs using DX7 presets, I see a parallelism between textural function and formal function. Core-layer sounds are used throughout the track. This is evident in songs already discussed—BASS 1 is used in every section of “When I Think of You” and “What is Love?,” excepting only the breakout choruses, and E. PIANO 1 is used in every section of “Running in the Family” as well—and also in several other songs that use both E. PIANO 1 and BASS 1 throughout, such as Madonna’s “Live to Tell” (#1 US June ’86, #2 UK Apr. ’86) and Gloria Estefan’s “Rhythm Is Gonna Get You” (#1 US Mar ’88, #15 UK Dec. ’88). The melodic layer is featured in verses, bridges, and choruses but omitted for intros, interludes, and the like, and HARMONICA and CLAV 1 both fit into the song this way. CLAV 1 and BRASS 2 both also solidify their status as melodic layer instruments by sharing a melodic line with the voice in the verses of those songs. The novelty layer tends to be featured in intros and interludes, though it will also interject in the gaps left by the melodic layer during the verses and choruses, as seen with CALIOPE, FLUTE 1, and VIBES.
[2.19] The form of a pop/rock song, then, reflects the different kinds of textural-functional roles, another example of markedness assimilation. The core layers ground the texture and unify each of the song sections. The novelty layer contains non-essential elements that nevertheless demand attention; thus, they must be kept distinct from the melodic layer. As the melodic layer governs the verses and choruses, the novelty layer is relegated to only the non-essential formal sections or otherwise takes on a secondary or countermelodic role within essential sections.
[2.20] Implied in this power struggle between melody and novelty layers is a commonality. Owsinski recognizes this in his Mixing Engineer’s Handbook, writing, “You can think of a fill element [the novelty layer] as an answer to the lead [the melodic layer]” (2013, 12). The melodic layer provides the most important motives and carries the lyrics, but both functional layers are essentially melodically oriented.
Example 13. DX7 presets and their typical functional layers
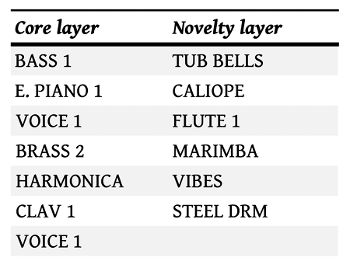
(click to enlarge)
Example 14. Opposition table for twelve DX7 presets
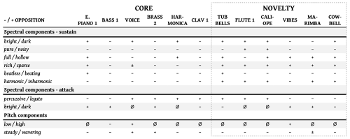
(click to enlarge)
[2.21] Again, while timbre is not a determining factor when assigning functional layers, timbral qualities nevertheless tend to group together along the same lines as functional layers, so that core-layer sounds share certain timbral features and the novelty-layer sounds share others. The same DX7 presets consistently fall into certain functional layers, even across different albums and artists (Example 13). In Example 14, I have grouped the twelve presets as belonging typically to the core or novelty layers based on my earlier categorizations of their textural function. The table reveals the consistency in what timbral features a core-layer sound will have. In general, the core layer has more negative designations in the opposition table. Because unmarked timbral attributes receive a negative designation and marked attributes a positive designation, the larger number of negatives in the core layers indicate a more mainstream sound. Note especially that core presets are very likely to be full, rich, and harmonic. These are timbral qualities that help these sounds to blend together into the song’s groove.
[2.22] The novelty layer is much more diverse and thus difficult to generalize in the same way as the core layers, but as a rule, novelty-layer sounds are more likely to receive positive designations for their timbral attributes. Novelty-layer sounds are far more often hollow, sparse, and inharmonic, to the point where these attributes seem almost to predict their deployment as novelty sounds before the song is even written. These are all marked timbral attributes, carrying greater semiotic weight in terms of musical meaning because of their non-conformity to the mainstream pop/rock sound. All of these features will draw attention to the novelty sounds, since they are the opposites of the common features of core layer sounds (full, rich, harmonic). Thus, the novelty sounds are better suited to hooks and solos—at least as long as the songwriter/producer wishes to have a more normative sound in the track.(33)
[2.23] Establishing timbral norms opens an opportunity for dialogic analysis in which the transgression of norms generates musical meaning, the subject of the following part of this article. In short, I posit that the typical goal of a core layer is to blend; the goal of the novelty layer, by contrast, is precisely not to blend.(34) I find that certain acoustic-timbral features, especially pure, full, and harmonic, are particularly conducive to allowing a timbre to blend, either with other instruments or with the human voice. Other oppositional features, like inharmonic and hollow, do not blend as well, and, as such, are particularly well-suited to colorful interjections, sweeteners, or ornaments. That certain DX7 presets retain the same roles consistently across many 1980s singles confirms these timbral norms. By establishing timbral norms, I open an opportunity for dialogic analysis in which the transgression of norms generates musical meaning, the subject of the following part of this article.
3. Timbre Narratives
[3.1] Not every song uses DX7 presets in expected ways, but timbre norms provide a way of framing these moments dialogically, as I will demonstrate through an analysis of “Do They Know It’s Christmas?” by Band Aid. The 1984 single, a #1 hit in the UK in December of 1984 and #13 in the US at the same time, features two DX7 presets—TUB BELLS and VOICE 1.(35) The use of both presets is more complex than the previous examples, blurring the boundaries between melody and novelty layers: TUB BELLS and VOICE 1, rather than remaining in their typical functional layers (novelty and melody, respectively), both take on new textural functions in the course of the track. Far from invalidating the norms I articulated in Part 2, I read this blurring as a fulfillment of the message of unity communicated through the lyrics.
Example 15. Form chart of “Do They Know It’s Christmas?” (1984)

(click to enlarge and listen)
[3.2] The form of “Do They Know It’s Christmas?” deviates from the typical verse-chorus pop/rock song: it is essentially a two-part form, in roughly equal proportions. The first part can be understood in verse-chorus terms, while the second is a kind of accumulative coda (Example 15).(36) In the first part, the lyrics paint a grim picture of contrast between the Western Christmastime and poverty and hunger in Africa, summarized in the title lyric, “Do they know it’s Christmastime at all?”; the second part, in stark contrast, breaks into a communal, exultant chorus, repeating the mantra “Feed the world.” Taken together, the two sections of “Do They Know It’s Christmas?” exemplify a relationship codified by Frank Samarotto as an expectation-infinity trope. Samarotto (2012) characterizes the first “expectation” section as something that sets up a lyrical and tonal problem that demands a resolution, which will come in the later infinity section. I will reference the two large parts of this song by the names “expectation section” and “infinity section” as I discuss musical meaning in this song.(37)
[3.3] The forming of the first of four iterations of the supergroup Band Aid occurred in 1984, in the midst of a famine in Ethiopia. Bob Geldof and Midge Ure put together 1980s British and Irish pop superstars such as Bono, Boy George, Phil Collins, and George Michael to make a one-off single, the proceeds of which would be donated to a charity fund for the famine. While the proceeds surely helped ameliorate the situation in Ethiopia, I would be remiss not to mention that the song has rightfully received a great deal of criticism for being Euro-centric, patronizing, and offensive—in other words, this song is an exemplar of the tendency in 1980s pop music to incorporate cultural references to the Global South, especially Africa, into pop music in a tokenizing way.(38) To begin, the title lyric itself is problematic. In Ethiopia, Christianity is in fact the dominant religion, having been adopted as the state religion in the fourth century—though interestingly, because they follow the Julian calendar, Ethiopian Orthodox Christians celebrate Christmas on January 7 instead of December 25, so depending on when you ask the question, the answer to “Do They Know It’s Christmas?” may in fact still be “no,” but only because it would seem a bit early to an Ethiopian Orthodox Christian.
[3.4] The rest of the lyrics do no better, portraying a delusionally ghastly portrait of the continent of Africa. Lyrics such as “Where the only water flowing is / The bitter sting of tears” and “Where nothing ever grows / No rain nor rivers flow” seem to ignore the existence of the tropical forests and the Blue Nile river within Ethiopia’s borders as well as many other rivers and biomes outside of Ethiopia within Africa. Perhaps the most perplexingly disturbing line is Bono’s statement, “Tonight thank God it’s them instead of you,” for which I find a well-intentioned motivation difficult to imagine. British journalist Bim Adewunmi (2014) critiques the entire mindset in a piece for The Guardian:
There exists a paternalistic way of thinking about Africa, likely exacerbated by the original (and the second, and the third) Band Aid singles, in which it must be “saved,” and usually from itself. We say “Africa” in a way that we would never say “Europe,” or “Asia.” It’s easy to forget, for example, that the [Ebola] virus made its way to Nigeria – Africa’s most populous country and, for many, a potential Ebola tinderbox – and was stamped out only by the efforts of a brave team of local healthcare workers. The popular narrative always places those of us in the west in the position of benevolent elders, helping out poor Africans, mouths always needy and yawning, on their constantly blighted continent, and leaves out harder to pin down villains: local corruption, yes, but also global economic policies that do little to pull some countries out of the depths of entrenched poverty.
As Adewunmi notes, the problematic lyrics in the fourth single were only marginally better, proving that not all the misconceptions can be written off as quaint 1980s insensitivity. British-Ghanaian hip hop artist Fuse ODG (2014) was asked to participate in the latest reincarnation, Band Aid 30, but he refused to participate after locating problematic notions throughout the lyrics that he could not support:
I pointed out to [producer Bob Geldof] the lyrics I did not agree with, such as the lines “Where a kiss of love can kill you and there’s death in every tear” and “There is no peace and joy in west Africa this Christmas.” For the past four years I have gone to Ghana at Christmas for the sole purpose of peace and joy. So for me to sing these lyrics would simply be a lie. In truth, my objection to the project goes beyond the offensive lyrics. I, like many others, am sick of the whole concept of Africa—a resource-rich continent with unbridled potential—always being seen as diseased, infested and poverty-stricken. In fact, seven out of 10 of the world’s fastest growing economies are in Africa . . . . Returning to London at the age of 11, being African was not something to be proud of because of all the negative connotations it conjured up, and it drove me to be almost ashamed of who I was. . . . [T]hough shock tactics and negative images may raise money in the short term, the long-term damage will take far longer to heal.
Example 16. Transcription of the chorus going into the bridge of “Do They Know It’s Christmas?” (1:34–2:10)

(click to enlarge and listen)
[3.5] This mismatch between Europeans’ notions of Christmastime and their imaginations of Ethiopia can be related to the novelty layer of this song. TUB BELLS is used in nearly every section of “Do They Know It’s Christmas?” as the novelty layer, the same as it is in “What Is Love?” and many other songs using this preset. Oftentimes, such as the intro and verse 1, the role of TUB BELLS is to simply toll on middle C. The lyric “And the Christmas bells that ring there / Are the clanging chimes of doom” summons the TUB BELLS to play a full-fledged motive, which will recur in the chorus (Example 16). TUB BELLS undoubtedly is used here as a timbral signifier of Christmastime; moreover, I interpret the prominent use of TUB BELLS as highlighting the stark and disturbing opposition present in the lyrics between a European Christmas Day celebration and whatever sight in Ethiopia would warrant “clanging chimes of doom.” Even though TUB BELLS is itself primarily a European orchestral instrument, its use in the novelty layer continues the trend of exoticization via the novelty layer.
[3.6] At the very end of the chorus, immediately before the bridge, VOICE 1 enters with a brand new melody that is abruptly abandoned (Example 16, fourth stanza); as the bridge begins, VOICE 1 is instead used as a pad, playing chords to support the vocal melody. VOICE 1, then, is introduced in the melodic layer, but interrupts itself to take on a new role as the harmonic filler layer. This kind of dislocation is one of Samarotto’s typical features of the expectation section from his expectation-infinity trope: the listener now expects the motive to be taken up again and drawn to a conclusion. VOICE 1’s jump between functional layers further underscores the feeling of incompleteness when VOICE 1 interrupts its own melody: not only will listeners expect the melody itself to return, but they might also expect VOICE 1 to return to its initial position in the melodic layer. Indeed, VOICE 1 fulfills this expectation in the infinity section, regaining its melodic role and taking up the interrupted motive again.
Example 17. Transcription of the infinity section of “Do They Know It’s Christmas?” (2:16–3:12)

(click to enlarge and listen)
Example 18. Entry of each line of the cumulative texture in the infinity section

(click to enlarge)
[3.7] Example 17 shows the fully assembled texture of the infinity section (in other words, a transcription of the texture at the point where every line has entered). Because this section is accumulative, not all these lines are present at the beginning of the section. Example 18 indicates the entry of each motive into the texture. The functional bass, explicit beat, and harmonic filler layers accompany VOICE 1 from the very beginning of the infinity section. VOICE 1 now continues its melody beyond the initial motive, following it with cadential material and resulting in a complete four-measure phrase (Example 17).
[3.8] The TUB BELLS enter next, and after that, the vocals, which enter with only half of the melody shown in Example 17—the first and second measures, “Feed the world.” This creates a call-and-response effect between the melodic layer as instantiated by the vocals and the novelty layer (TUB BELLS), generating an oppositional effect similar to the ones found between the melodic and novelty layers in “What’s Love Got to Do with It” and in “Running in the Family.” This opposition is reconciled—the opposing melodic and novelty layers are synthesized—once the texture has fully assembled. When the vocals begin singing the full four-bar melody as transcribed in Example 17, during the third and fourth measures of this looping music, the vocals and TUB BELLS play the same melody. This signals that TUB BELLS is moving out of the novelty layer and, remarkably, into the melodic layer.
[3.9] Just as the fluidity of VOICE 1’s textural function was reflective of the expectation-infinity trope, so too is the use of TUB BELLS as a melody sound. As I discussed in Part 2 of this article, TUB BELLS is not suitable in the context of mainstream 1980s popular music for a conventional melody sound because of its many marked timbral characteristics, especially inharmonic and sparse. But during the infinity section, everyone in the supergroup joins in a communal, mantra-like chant, and even TUB BELLS is welcome to join the jubilation. The synthesis of the two opposed textural layers, melodic and novelty, creates this timbral narrative. Under typical pop-rock circumstances, perhaps the sound of TUB BELLS as a melodic instrument would sound too busy and noisy, but it works in the context of a joyous infinity section.
4. Conclusion
[4.1] I established timbral norms for functional layers in this article in order to open the opportunity for dialogic analysis, where meaning is created wherever norms are transgressed. In “Do They Know It’s Christmas?,” VOICE 1 and TUB BELLS both cross from one timbral-functional category to another, in alignment with the major formal division of this two-part form. Their movement across categories supports through timbre both the formal structure and the lyrical message: VOICE 1 created a sense of expectation by foreshadowing its future status as a melody sound in the expectation section; TUB BELLS, though not typically a suitable melody sound, switched from novelty to melody in the infinity section, as if happily joining in the communal mantra.
[4.2] The work that preceded this discussion has much larger implications for the field of music theory, however. Much previous work has been devoted to studying the effects of pitch and rhythmic transformations on the narrative trajectory of a piece. My work demonstrates that, especially for 1980s popular music, analysts may create compelling narratives by studying the interactions between the lesser-studied domains of timbre, instrumentation, genre, and identity. Attention to timbre in particular reveals a great deal about the culture within which music was produced: in this case, the musical and timbral results of globalization and computerization in the 1980s. The methodology of spectrogram analysis presented here is one way that music theorists may begin to engage these topics in their own work.
Megan L. Lavengood
George Mason University
Fairfax, Virginia, USA
meganlavengood@gmail.com
Works Cited
Adewunmi, Bim. 2014. “Band Aid 30: Clumsy, Patronising and Wrong in so Many Ways.” The Guardian, November 11, 2014. https://www.theguardian.com/world/2014/nov/11/band-aid-30-patronising-bob-geldof-ebola-do-they-know-its-christmas.
Agazzari, Agostino. [1607] 1998. “Of Playing upon a Bass with All Instruments and of Their Use in a Consort.” In Source Readings in Music History, eds. Oliver Strunk and Leo Treitler, trans. Oliver Strunk, 622–8. W. W. Norton & Company.
Ahrens, Christian. 2006. “Toy Stops.” In The Organ: An Encyclopedia, eds. Douglas Busch and Richard Kassel, 571. Routledge.
Blake, David K. 2012. “Timbre as Differentiation in Indie Music.” Music Theory Online 18 (2). http://mtosmt.org/issues/mto.12.18.2/mto.12.18.2.blake.php.
Cateforis, Theo. 2011. Are We Not New Wave? Modern Pop at the Turn of the 1980s. University of Michigan Press.
Cogan, Robert. 1984. New Images of Musical Sound. Harvard University Press.
Devaney, Johanna. forthcoming. “Audio Tools for Music Corpus Studies.” In Oxford Handbook of Music and Corpus Studies, eds. Daniel Shanahan, Ashley Burgoyne, and Ian Quinn. Oxford University Press.
Erickson, Robert. 1975. Sound Structure in Music. 1st ed. University of California Press.
Fales, Cornelia. 2002. “The Paradox of Timbre.” Ethnomusicology 46 (1): 56–95. https://doi.org/10.2307/852808.
Feld, Steven. 1988. “Notes on World Beat.” Public Culture 1 (1): 31–37. https://doi.org/10.1215/08992363-1-1-31.
François, Jean-Charles. 1991. “Organization of Scattered Timbral Qualities: A Look at Edgard Varèse’s Ionisation.” Perspectives of New Music 29 (1): 48–79. https://doi.org/10.2307/833066.
Gleason, Harold. 1995. Method of Organ Playing. Edited by Catherine Crozier Gleason. 8th ed. Prentice Hall.
Goodchild, Meghan, and Stephen McAdams. 2018. “Perceptual Processes in Orchestration.” In The Oxford Handbook of Timbre, eds. by Emily I. Dolan and Alexander Rehding. Oxford University Press. https://www.oxfordhandbooks.com/view/10.1093/oxfordhb/9780190637224.001.0001/oxfordhb-9780190637224-e-10.
Harcus, Aaron. 2017. “The Varieties of Tone Presence: On the Meanings of Musical Tone in Twentieth-Century Music.” PhD diss., City University of New York.
Hardman, Kristi. 2020. “A Set of Continua for the Acoustic Properties of Tanya Tagaq’s Katajjaq Sounds.” Paper presented at the Music Theory Midwest 31st Annual Conference, July 9.
Hatten, Robert S. 1994. Musical Meaning in Beethoven: Markedness, Correlation, and Interpretation. Indiana University Press.
Heidemann, Kate. 2014. “Hearing Women’s Voices in Popular Song: Analyzing Sound and Identity in Country and Soul.” PhD diss., Columbia University.
—————. 2016. “A System for Describing Vocal Timbre in Popular Song.” Music Theory Online 22 (1). https://mtosmt.org/issues/mto.16.22.1/mto.16.22.1.heidemann.html.
Helmholtz, Hermann L. F. 1875. On the Sensations of the Tone as a Psychological Basis for the Theory of Music. Translated by Alexander J. Ellis. Longmans, Green, and Co.
Krimphoff, Jochen, Stephen McAdams, and Suzanne Winsberg. 1994. “Caracterisation Du Timbre Des Sons Complexes. II: Analyses Acoustiques et Quantification Psychophysique [Characterization of the Timbre of Complex Sounds. II: Acoustic Analyses and Psychophysical Quantification].” Journal de Physique 4 (C5): 625–28.
Lavengood, Megan. 2019. “‘What Makes It Sound ’80s?’: The Yamaha DX7 Electric Piano Sound.” Journal of Popular Music Studies 31 (3).
Marubbio, M. Elise. 2009. Killing the Indian Maiden. University Press of Kentucky.
McAdams, Stephen. 1999. “Perspectives on the Contribution of Timbre to Musical Structure.” Computer Music Journal 23 (3): 85–102.
McAdams, Stephen, and Bruno L. Giordano. 2008. “The Perception of Musical Timbre.” In Oxford Handbook of Music Psychology, 72–80. Oxford University Press. https://doi.org/10.1093/oxfordhb/9780199298457.001.0001.
McCreless, Patrick. 1991. “Syntagmatics and Paradigmatics: Some Implications for the Analysis of Chromaticism in Tonal Music.” Music Theory Spectrum 13 (2): 147–78. https://doi.org/10.2307/745896.
Meintjes, Louise. 2003. Sound of Africa!: Making Music Zulu in a South African Studio. Duke University Press.
Moore, Allan F. 2012. Song Means: Analysing and Interpreting Recorded Popular Song. Ashgate.
ODG, Fuse. 2014. “Why I Had to Turn down Band Aid.” The Guardian, November 19, 2014. https://www.theguardian.com/commentisfree/2014/nov/19/turn-down-band-aid-bob-geldof-africa-fuse-odg.
Owsinski, Bobby. 2013. The Mixing Engineer’s Handbook. 3rd ed. Cengage Learning PTR.
Pedersen, Paul. 1965. “The Mel Scale.” Journal of Music Theory 9 (2): 295. https://doi.org/10.2307/843164.
Peeters, Geoffroy, Bruno L. Giordano, Patrick Susini, Nicolas Misdariis, and Stephen McAdams. 2011. “The Timbre Toolbox: Extracting Audio Descriptors from Musical Signals.” The Journal of the Acoustical Society of America 130 (5): 2902–16.
Ritchie, George H., and George B. Stauffer. 2000. Organ Technique: Modern and Early. Oxford University Press.
Russo, Frank A., Dominique T. Vuvan, and William Forde Thompson. 2019. “Vowel Content Influences Relative Pitch Perception in Vocal Melodies.” Music Perception: An Interdisciplinary Journal 37 (1): 57–65. https://doi.org/10.1525/mp.2019.37.1.57.
Saldanha, EL, and John F. Corso. 1964. “Timbre Cues and the Identification of Musical Instruments.” Journal of the Acoustical Society of America 130 (5): 2021–26.
Samarotto, Frank. 2012. “The Trope of Expectancy/Infinity in the Music of the Beatles and Others.” Paper presented at the the joint meetings of the American Musicological Society, the Society for Ethnomusicology, and the Society for Music Theory, New Orleans, LA, November 2.
Sandell, Gregory J. 1995. “Roles for Spectral Centroid and Other Factors in Determining ‘Blended’ Instrument Pairings in Orchestration.” Music Perception: An Interdisciplinary Journal 13 (2): 209–46. https://doi.org/10.2307/40285694.
Scotto, Ciro. 2017. “The Structural Role of Distortion in Hard Rock and Heavy Metal.” Music Theory Spectrum 38 (2): 178–99. https://doi.org/10.1093/mts/mtw013.
Sethares, William A. 2005. Tuning, Timbre, Spectrum, Scale. 2nd ed. Springer.
Slawson, Wayne. 1981. “The Color of Sound: A Theoretical Study in Musical Timbre.” Music Theory Spectrum 3 (1): 132–41. https://doi.org/10.2307/746139.
—————. 1985. Sound Color. University of California Press.
Spicer, Mark. 2004. “(Ac)Cumulative Form in Pop-Rock Music.” Twentieth-Century Music 1 (1): 29–64. https://doi.org/10.1017/S1478572204000052.
Vail, Mark. 2002. “Yamaha DX7 6-Operator Synthesizer.” Keyboard, June 2002.
Wallmark, Zachary. 2018. “The Sound of Evil: Timbre, Body, and Sacred Violence in Death Metal.” In The Relentless Pursuit of Tone: Timbre in Popular Music, eds. Robert Wallace Fink, Melinda Latour, and Zachary Wallmark, 43–64. Oxford University Press.
Discography
Discography
Band-Aid. 1984. “Do They Know It’s Christmas?” Phonogram FEED 112.
Bolton, Michael. 1989. Soul Provider. Columbia CT45012.
Estefan, Gloria. 1987. “Rhythm Is Gonna Get You.” Epic 49-06772.
Jackson, Janet. 1986. Control. A&M CD-3905.
Jones, Howard. 1984. Human’s Lib. WEA 2 40335-2.
Level 42. 1987. Running in the Family. Polydor 831 593-2.
Madonna. 1986. “Live to Tell.” Sire 9 28717-7.
—————. 1989. “Like a Prayer.” Sire 925 844-2.
Michael, George. 1984. “Careless Whisper.” Epic A 4603.
Turner, Tina. 1984. Private Dancer. Capitol ST-12330.
Wham!. 1984. Make It Big. Epic 28·3P-555.
Footnotes
* This paper originated as part of my dissertation, advised by Mark Spicer; I thank him and my whole dissertation committee for guiding the project. This research was presented as a conference paper titled “A New Approach to Analysis of Timbre: A Study in Timbre Narratives and Instrumentation in 1980s Pop” at the 41st Annual Meeting of the Society for Music Theory and other venues, where I received feedback from Lori Burns, Eric Drott, Sumanth Gopinath, and Marianne Wheeldon that ended up defining the cultural angle of this essay. Many other scholars helped shape this paper, including Bryn Hughes, Olivia Lucas, and Nancy Murphy. Finally, I thank my anonymous reviewers for their time and feedback.
Return to text
1. Moore defines the melody layer through the voice, writing that its “function is to make explicit one or more melodies. . . . We will find primary and, often, secondary melodic lines. The primary line, of course, is the tune, and its essential role is to enable the articulation of the song’s lyrics” (2012, 20).
Return to text
2. The idea that spectrograms are not an adequate representation of timbre takes slightly different forms in each of these writings, but all relate to the significance of human perception and experience. For Fales (2002), an important concept is that humans imperfectly identify sound sources and thus make associations with the timbre based on the presumed source regardless of whether or not that perceived source is the true source. For Blake (2012) and Heidemann (2014), the spectrogram is not as relevant as the intuitive and immediate understanding of timbre that occurs during regular listening without any visual aid. In Lavengood (2019), spectrograms are shown to contradict common assessments of timbre, and these contradictions are attributed to the embodied experience of performance.
Return to text
3. These software programs vary widely in terms of the control they offer over different parameters, however, which can drastically affect analysis.
Return to text
4. The spectrograms throughout this article have been created with iZotope RX4 software. Settings for the spectrograms are as follows. The frequency scale is the Mel scale (cf. Pedersen 1965). As summarized by Devaney (forthcoming), “the sizes of the frequency bands are more closely linked to the frequency mapping of human hearing in that the frequency mapping is linear below 1 kHz and logarithmic above.” The amplitude range of the spectrogram goes from –92.8 dBFS (low) to 0 dBFS (high). The software automatically varies the time and frequency resolution of the Fourier transform to achieve what the iZotope manual calls the “best spectrogram sharpness in every area of the time-frequency plane.” The fast Fourier transform size is set to 2048 frames, a high resolution, but one that isn’t so high that it would obscure onsets. The window is set to cos3(x) in order to reduce vertical blurriness that would obscure the frequency of a signal (that is, leakage between frequency bins). The frequency and time overlap of the windows are both set to 4x. For more information, see the iZotope RX user’s manual on “Spectrogram Settings.”
Return to text
5. Of course, it would be possible to have an animated spectrum plot show change through time.
Return to text
6. Because the timbral qualities of a sound changes through time, analysts often break the entire sound signal into portions. I use language that refers to the traditional ADSR envelope used in sound synthesis: Attack, Decay, Sustain, Release. Other timbre research will refer to the sustain as the “steady state” portion of the sound, and the attack as the “onset” of the sound.
Return to text
7. Several of my oppositions are originally Cogan’s (1984, 133–40). Often, but not always, I have changed the language to avoid overly technical vocabulary and rely instead on common language terms that reflect listener experience.
Return to text
8. Cogan valences each term within an opposition as either positive or negative, based on whether they possess “low energy” or “high energy” (1984, 126). This allows him to total up a score for each sonic moment he analyzes: plus signs and negative signs cancel one another out, and a total sum can be found. Cogan then graphs these sums to represent “directed spectral flow.”
Return to text
9. This term was introduced to the field of music theory by Hatten, who in turn borrows the concept from structural linguistics. Patrick McCreless (1991, 61) used this term in print before Hatten but cites a draft of Hatten’s (1994) book for his use of the concept.
Return to text
10. I grant that there are several subtle differences between my performance and the one on the original track—velocity, microtiming, and aftertouch pressure are all virtually impossible to replicate exactly as performed. For simplicity’s sake, I am also disregarding mixing and production effects such as reverb, compression, and equalization. While all these things will affect the timbre of a sound signal, I maintain that the differences are subtle enough to be ignored for my purposes in this article.
Return to text
11. The original Yamaha DX7 was produced only from 1983 to 1986. After 1986, Yamaha produced successors to the DX7, the DX7II and the DX7II FD. There were no further DX7II FDs produced after 1989, which likely solidifies the role of the DX7 as a quintessentially ’80s synthesizer. See Vail 2002, 130.
Return to text
12. As a disclaimer, the guitar sounds may not technically be completely clean; sometimes a small amount of amplifier distortion, compression, or overdrive may be used. But to the untrained ear (such as mine), the sounds are basically clean, and I find this good enough for the purposes of my cultural analysis. I thank Drew Fleming for lending his expertise on guitar timbre and being my primary consultant on this issue.
Return to text
13. Scotto does not publish what equipment was used to record his Example 5(a), but I confirmed in private correspondence with Scotto that the signal comes from playing the pitch A2 (110 Hz) on an ESP Eclipse guitar with James Hetfield pickups through a Mesa Boogie Mark V amplifier on Channel 3.
Return to text
14. Scotto (2017) claims the signal from his Example 5(a), my Video Example 2, “only contains odd harmonics” (180), or to use my terminology, is hollow. This is incorrect. As shown in the spectrogram in Video Example 2, the signal from Scotto’s Example 5(a) is in fact full.
Return to text
15. I chose this number by examining the centroids of all the samples I discuss in Part 2. The samples fell into two groups at around 700 and 1900 Hz.
Return to text
16. Centroids fluctuate through time. In an effort to minimize my annotations, I have only shown the median centroid for the sample.
Return to text
17. The significance of this parameter has been described by Krimphoff, McAdams, and Winsberg (1994) and Peeters et al. (2011).
Return to text
18. Harmonic, partial, and overtones have slightly different meanings. Partial is the most general term, meaning any one of the distinct spectral elements of a sound signal. Etymologically, the term refers to its role as part of the complex timbre of the sound signal, which comprises many such parts. Overtone is essentially the same as a partial, but the term cannot be applied to the fundamental—overtones are, strictly speaking, partials that occur over the fundamental. Harmonic has the most restricted usage: a harmonic is a partial whose frequency is in a whole-number ratio with the fundamental frequency; in other words, it must be a part of the harmonic series.
Return to text
19. Here, I think primarily of Cogan (1984), who had only one opposition addressing the attack, attack/no-attack. Approaches to timbre analysis that focus on vowel sounds (either in vocal timbres or as analogies), such as Slawson 1981, also tend to pay little attention to the attack.
Return to text
20. Listeners were able to identify the source of a tone with 50% greater accuracy if the attack (onset) of the sound was included in the sample, as opposed to a sample that cuts out the attack and plays only the sustained portion of the sound.
Return to text
21. One concrete example of this is a study by Russo and Vuvan (2019), who demonstrate that the brightness of vowel sounds affect listeners’ perception of an interval’s size.
Return to text
22. For readers who remain skeptical, Part II of Cogan’s (1984, 124–125) book opens with a philosophical defense of the use of binaries as the basis for understanding, drawing on work by C. S. Peirce and other philosophers. To summarize briefly, much of our understanding of the world comes from contrasting objects with other objects. Inherent in such a comparison is a binarism that opposes one object with another. This is one way in which we experience differences. The idea of binarism has influenced philosophers from Plato to Hegel, so Cogan observes. There is further empirical support for the use of binaries in studies of music perception. Stephen McAdams (1999) deals with the perception of musical timbre, and his experiments demonstrate that binaries might be an effective way to categorize timbre in at least some cases. From a study asking participants to rank the similarity between 153 pairs chosen among 18 timbres, listeners seem to have conceived of attack times as basically short or long, with little middle ground.
Return to text
23. Much ink has been spilled on the concept of “blend.” Megan Goodchild and Stephen McAdams (2018) define blend as “the result of the perceptual fusion of various instrument sounds, providing the illusion of originating from a single sound source.” While traditional orchestration treatises will address this issue mainly through examples from the literature and generalization from those examples, Goodchild and McAdams explicitly attend to the role of timbral attributes in blending. Through their extensive modeling of the perceptual processes involved in the perception of blend, they detail how similarity among different timbral profiles facilitates blending, while distinctive timbral profiles will resist blending. Another older study of blend in orchestration is Sandell 1995.
Return to text
24. I am grateful to the colleagues who enhanced my discussion with these various connections: Judith Ofcarcik for the connection to organ registration, Greg McCandless for the mixing engineering terminology and the Owsinski text, and William Rothstein for the connection to Agazzari.
Return to text
25. See, for example, Ritchie and Stauffer 2000, 373–5; Gleason 1995, 6–8; and Ahrens 2006, 571.
Return to text
26. Agazzari does not have a category that corresponds to my melody category. I presume this is because he is focusing on instruments which might be reading from a continuo part, and the melody instrument would instead have its own score apart from the continuo.
Return to text
27. M. Elise Marubbio describes this trope as it appears in film: “the Sexualized Maiden embodies enhanced sexual and racial difference that results in a fetishizing of the figure. . . . Hollywood film taps into this fetishism by heightening the figure’s sexuality and her potential for physically harming white male characters, using it as evidence of her immorality, innate savagery, and potential to destroy American society. As a result, she becomes the female representation of the ignoble savage” (2009, 7).
Return to text
28. Spectral centroids for each presets are as follows: E. PIANO 1, 528 Hz; HARMONICA, 1834 Hz; FLUTE 1, 839 Hz; CALIOPE, 792 Hz.
Return to text
29. Spectral centroids for each presets are as follows: BASS 1, 408 Hz; BRASS 2, 2188 Hz; CALIOPE, 792 Hz; TUB BELLS, 1861 Hz.
Return to text
30. The spectral centroid for CLAV 1 is 1975 Hz.
Return to text
31. The spectral centroid for VIBES is 838 Hz.
Return to text
32. The spectral centroid for MARIMBA is 1692 Hz.
Return to text
33. I discuss non-normative tracks beginning in Part 3 below.
Return to text
34. This is reinforced by Blake (2012), who specifies a heterogenous texture as a marker of indie music and a homogenous texture as a marker of mainstream music. He writes, “Homogeneity means both the lack of variety of sounds within the songs’ given soundscapes, and also the similarity of sounds between the two songs and larger generic expectations relative to the possible range of electric guitar sounds,” whereas timbral heterogeneity refers to “an increased sense of recording and songwriting craft which produces unusual sounds.”
Return to text
35. In an exchange on Twitter, Midge Ure verified that these were DX7 sounds: “Dx7 features heavily on there. The bells and flutes were the most prominent sounds. Impossible to program!” VOICE 1 is likely the “flute” sound that Ure references here. Midge Ure (@midgeure1), Twitter, October 20, 2015, 2:02 p.m., https://twitter.com/midgeure1/status/656530976844173316.
Return to text
36. The term “accumulative” here comes from Spicer (2004), who details the functions of cumulative forms in several examples of pop/rock music.
Return to text
37. Samarotto cites “Hey Jude” by the Beatles as the exemplar of this trope. Expectancy sections are characterized by text that is non-narrative, refers to a change of state, acceptance of an upcoming state, points to future possibility, and makes temporal references; and music that uses rising or otherwise incomplete-sounding gestures, is formally incomplete, is tonally incomplete, uses lighter instrumentation, and features temporal dislocations. Infinity sections feature text that has repeating lyrics, fragmentary lyrics, or no lyrics, which may make explicit what was hinted at in the expectancy section; the music has a repeating chord pattern, uses long tones and melodic stasis, and has a slower pacing.
Return to text
38. This was discussed previously in connection with the novelty layer in Part 2 of this article. For more writing on this subject, see Cateforis 2011, Feld 1988, and Meintjes 2003.
Return to text
Copyright Statement
Copyright © 2020 by the Society for Music Theory. All rights reserved.
[1] Copyrights for individual items published in Music Theory Online (MTO) are held by their authors. Items appearing in MTO may be saved and stored in electronic or paper form, and may be shared among individuals for purposes of scholarly research or discussion, but may not be republished in any form, electronic or print, without prior, written permission from the author(s), and advance notification of the editors of MTO.
[2] Any redistributed form of items published in MTO must include the following information in a form appropriate to the medium in which the items are to appear:
This item appeared in Music Theory Online in [VOLUME #, ISSUE #] on [DAY/MONTH/YEAR]. It was authored by [FULL NAME, EMAIL ADDRESS], with whose written permission it is reprinted here.
[3] Libraries may archive issues of MTO in electronic or paper form for public access so long as each issue is stored in its entirety, and no access fee is charged. Exceptions to these requirements must be approved in writing by the editors of MTO, who will act in accordance with the decisions of the Society for Music Theory.
This document and all portions thereof are protected by U.S. and international copyright laws. Material contained herein may be copied and/or distributed for research purposes only.

Prepared by Michael McClimon, Senior Editorial Assistant
Number of visits:
28044