Alanis Morissette’s Voices
Drew Nobile
KEYWORDS: voice, timbre, form, persona, popular music, Alanis Morissette
ABSTRACT: Combining the slick production of post-grunge rock with raw, feminist lyrics reminiscent of Riot Grrrl punk, Alanis Morissette’s 1995 album Jagged Little Pill introduced a new rock femininity that rippled throughout the late 1990s. As several commentators have discussed, though, Morissette’s pop-critical reception as the quintessential “angry white female” overlooks the broad range of social and emotional content presented throughout the album. This expressive range comes not only from Morissette’s lyrics but also—perhaps especially—from her versatile and idiosyncratic vocal delivery. In this article, I take a detailed look at how Morissette uses her voice across Jagged Little Pill to express aspects of her album persona. I begin by identifying Morissette’s primary palette of six vocal styles, which I term “speech-song,” “modal voice,” “belt,” “soft voice,” “sweet voice,” and “squeal.” Each of these styles has its own mode of delivery, which I demonstrate through a set of binary parameters, and its own timbral profile, which I demonstrate using spectral analysis. I show how Morissette strategically deploys her vocal palette throughout the album for expressive effect, synchronizing with not only her songs’ lyrics but also their form. In so doing, my analysis shows how voice can serve a fundamentally structural role, one at least as powerful as harmony or melody in shaping a song’s formal process.
DOI: 10.30535/mto.28.4.6
Copyright © 2022 Society for Music Theory
Introduction
Example 1. Alanis Morissette on the cover of Rolling Stone Magazine, issue 720 (November 2, 1995), with the caption “angry white female”

(click to enlarge)
[1.1] Alanis Morissette’s Jagged Little Pill, released in June 1995, is one of the most iconic albums of the 1990s. It ranks on Billboard’s album charts as the #1 album of 1996, the #1 album of the entire 1990s, and the #7 album of all time; it took home four Grammy Awards in 1996, including Album of the Year; it was adapted into a Tony-winning Broadway musical in 2020; and it single-handedly caused an entire generation to think very deeply about what does and does not qualify as irony.(1) Arriving as alternative rock was solidifying its place at the center of mainstream popular music, Morissette’s album combined the slick production aesthetic of the post-grunge era with raw, feminist lyrics reminiscent of Riot Grrrl punk (see Schilt 2003 and Fournier 2015, 41–48). The success of the album’s lead single “You Oughta Know”—a furious and vulgar diatribe excoriating a selfish ex-lover—led contemporary critics to pigeonhole Morissette’s persona as the quintessential “angry white female,” as she was dubbed on a November 1995 cover of Rolling Stone Magazine (Example 1). However, that assessment oversimplifies the broad range of social and emotional content present throughout the album, as several commentators have noted (Fournier 2015, 1–13; Abdurraqib 2017; Whiteley 2000, 5–6). This expressive range comes not only from Morissette’s lyrics but also—perhaps especially—from her versatile and idiosyncratic vocal delivery. Several scholars have discussed aspects of Morissette’s singing style on the album, including her strategic combination of head and chest voice (Fournier 2015, 48–52), her use of paralinguistic sounds like cry breaks and yodels (Lacasse 2010), and sparse but narratively significant production effects on her vocal track (Burns 2010). In this article, I show how these individual elements form part of a broader, album-spanning strategy wherein voice and lyrics combine to express various aspects of Morissette’s persona. As I demonstrate, Morissette manipulates various aspects of her delivery to create a primary vocal palette of six distinct styles, each of which has its own timbral profile and expressive connotations. Furthermore, I show that throughout the album, Morissette’s six vocal styles synchronize with not only her songs’ lyrics but also their form. My analysis thus shows how voice can serve not only an expressive role but also a structural role, one at least as powerful as harmony or melody in shaping a song’s formal process.
The Jagged Little Pill Persona
[2.1] Vocal sound is central to how listeners interpret a song’s persona. I use “persona” here to refer to the vocal character taken on by the singer in the context of that particular song—the person we perceive to be singing the song to us.(2) Ascertaining the singing persona’s identity is a central concern when we listen to popular songs—in Nina Eidsheim’s words, “the foundational question asked in the act of listening to a human voice is Who is this? Who is speaking?” (2019, 1; see also Moore 2012, 179). We generally understand the persona to be the lyrical narrator, the one relaying the story in the text, and if the lyrics contain first-person pronouns we usually equate this lyrical “I” with the singing persona. There are exceptions, however, in which case the lyrics are enclosed in implied quotation marks, the narrator relaying the words of a different character, the song’s protagonist. A song’s persona is also distinct from its performer—i.e., the actual person whose voice we hear. The relationship between persona and performer is a central factor in our perception of authenticity: generally speaking, the more we perceive the two as equivalent, the more we will interpret the song as an authentic expression. “Authentic” thus correlates with “unmediated,” as Allan Moore has described (Moore 2002, 213): any perceived technologies, training, commercial concerns, co-writers, or other external agents that transform performer into persona will reduce how much authenticity we ascribe.(3)
[2.2] My discussion of Jagged Little Pill begins with the premise that the album as a whole is understood to be an expression of a single, consistent persona. This persona is presented as an authentic expression of Morissette the performer—that is, she is singing as herself. In most songs, we interpret the persona as the “I” in the lyrics; in this way, performer, persona, and protagonist are one and the same, both within each individual song and across the album’s various tracks. (We will see an exception to the persona-equals-protagonist rule in the analysis of “Perfect” below.) From this perspective, we quickly see that Morissette’s album persona is much more dynamic and varied than the “angry woman” so often cited by critics. Throughout the album, Morissette displays grief, pain, vulnerability, contentment, love, comfort, guilt, sarcasm, etc.—and, yes, plenty of anger. Together, these states present a multifaceted persona exemplifying humanity’s inherent contradictions, which Morissette gleefully summarizes in the verses of “Hand in My Pocket” (“I care, but I’m restless
Example 2. List of Jagged Little Pill’s songs with lyrical summaries and thematic categories
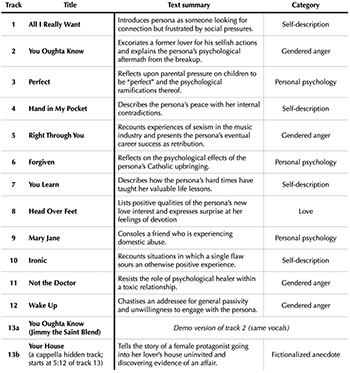
(click to enlarge)
[2.3] Example 2 lists Jagged Little Pill’s 13 songs in album order along with brief summaries of their lyrics; the album’s complete lyrics can be found in this article’s Appendix. As you can see, the album’s lyrical themes extend far beyond anger (though anger is not in short supply). What is also evident from this bird’s-eye view, though, is that the various topics coalesce into a detailed portrait of a single character; these are not unrelated vignettes, but different aspects of a central figure. In the third column of Example 2, I place each song’s lyrics into a general category based on what aspect of the persona it examines. Four songs demonstrate “gendered anger,” which the (female) persona expresses toward a male antagonist (an ex-lover in “You Oughta Know,” sexist industry executives in “Right Through You,” and current lovers in “Not the Doctor” and “Wake Up”). The anger expressed in these songs is specifically gendered because these personal situations are shown to represent broader gender dynamics, as I discuss later on. Another three songs fall under “personal psychology,” where the persona examines how her past experiences and upbringing have stayed with her, from parental pressures in “Perfect” to Catholicism in “Forgiven”; I also include “Mary Jane” in this category, even though the lyrics are mostly about Mary Jane’s experiences, because we learn a lot about Morissette’s persona from the way she talks to her friend about her abuse. I have labeled four other songs as “self-description,” in which the persona explains her outlook on life in general terms, including “All I Really Want,” “Hand in My Pocket,” “You Learn,” and “Ironic.”(4) Finally, “Head Over Feet,” which I’ve labeled simply as “love,” stands alone as somewhat of an antidote to the quartet of gendered anger songs, a smitten expression of devotion to a new love interest. There is one more song on the album, namely the hidden track “Your House,” appearing after 30 seconds of silence on the CD’s last track and containing only a single recorded vocal line with no accompaniment. This song is a rather creepy first-person account of sneaking into a lover’s home (or someone she imagines as her lover?) and discovering his relationship with another woman. Morissette has claimed that that song has “probably the only fictionalized moments on the whole record” (Gordon 2015), and it is the only song that proceeds as a narrative story, rather than focusing on a static state; I therefore label this song with its own category of “fictionalized anecdote.”
[2.4] The album’s lyrics, though, represent only half of the information we use to get to know Morissette’s album persona. The other half comes from the recorded sound of her voice.(5) As Simon Frith notes, words and sounds combine to make meaning in complex, sometimes contradictory ways:
What is the relationship between the voice as a carrier of sounds, the singing voice, making “gestures,” and the voice as a carrier of words, the speaking voice, making “utterances”? The issue is not meaning (words) versus absence of meaning (music), but the relationship between two different sorts of meaning-making, the tensions and conflicts between them. There’s a question here of power: who is to be the master, words or music? And what makes the voice so interesting is that it makes meaning in these two ways simultaneously. (Frith 1996, 186–87)
We can learn as much about the Jagged Little Pill album persona from the way Morissette sings as we do from the words she is singing. Just as the lyrical themes describe different aspects of the persona, Morissette’s various styles of vocal delivery communicate that persona’s different attitudes and emotional states. In the remainder of this article, I analyze Morissette’s vocal delivery across the album, focusing especially on those aspects she actively changes, as opposed to constant or innate characteristics. First, I demonstrate how Morissette manipulates a small set of parameters to create a palette of vocal styles with distinct timbral profiles and physiological implications. I then examine how Morissette deploys these vocal styles for expressive effect in an analysis of the album’s third track “Perfect.” Finally, I make the case that Morissette’s vocal delivery is not only an expressive feature but also a structural one, playing a central role in how we perceive a song’s form.(6)
Jagged Little Vocal Styles
[3.1] Morissette’s vocal sound is arguably the most salient aspect of Jagged Little Pill. Throughout the album, we hear her wail, creak, whisper, talk, laugh, and gasp, and with her voice’s dry production—generally placed front and center in the stereo mix with minimal studio effects—we sense that we are hearing Morissette’s raw sound uninhibited by decorum or external forces.(7) Producer and co-songwriter Glen Ballard describes Morissette’s recording process thus:
From a vocal standpoint, no one has that much courage. Everybody wants to fix their shit, she never did. She never did. She just wanted it to be that. And of course it was spectacular. But there was no Auto-Tune, no double track. We doubled certain things just for effects, but all those vocals are just her at the end of the night, singing something she just wrote. (Gordon 2015)
In other words, Morissette’s vocal sound solidifies her album persona’s claims of authenticity—we are led to interpret this persona as an expression of Morissette herself.(8)
[3.2] Noting Morissette’s expressive and varied use of her voice across the album, some writers have looked at specific elements of Morissette’s vocal style. Fournier, expanding on an analytical blog post by Patrick Dailly, interprets Morissette’s frequent transitions between head voice and chest voice as a “conflict between helplessness (the head-voice) and the quest to be in control (the chest-voice)” (Fournier 2015, 49).(9) Serge Lacasse, analyzing the hidden a cappella track “Your House,” notes Morissette’s expressive use of vocal fry, or “creaky voice,” which “seems to act as an indication of growing pain”; Lacasse also identifies what he calls “falsetto breaks” (what I call “yodel breaks,” discussed below), sounding “like a stylized cry or sob” (Lacasse 2010, 237–41). Lori Burns interprets the double-tracking in the prechorus of “You Oughta Know”—as noted, a rare studio effect on the album—as “a signal that this narrator is not merely addressing a personal situation but is speaking for a larger community” (Burns 2010, 187).
Example 3. Alanis Morissette’s six vocal styles on Jagged Little Pill and their associated vocal properties, presented as binaries with unmarked and marked values (the marked value indicated by gray shading)
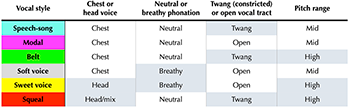
(click to enlarge)
[3.3] What I intend to show in this section is that these individual vocal expressions are part of a varied but consistent vocal palette, which Morissette employs strategically throughout Jagged Little Pill to express aspects of her album persona. This vocal palette comprises six fundamental vocal styles, which I call “speech-song,” “modal voice,” “belt,” “soft voice,” “sweet voice,” and “squeal.” As summarized in Example 3, Morissette differentiates these styles by manipulating four binary parameters of her vocal delivery: chest voice versus head voice; neutral phonation versus breathy phonation; constricted vocal tract versus open vocal tract (or twang versus no twang, as discussed below); and middle versus high pitch range. Within each binary, one value is neutral, or “unmarked,” and one is “marked.” The marked value is indicated by gray shading in the example. The idea is that the marked value is a more notable timbral feature than the unmarked one. For example, chest voice is unmarked and head voice is marked, since chest voice is the more common and more comfortable register in popular styles; head voice, then, seems more like a deliberate choice than chest voice. Categorizing sound quality through a set of binaries with marked and unmarked options comes from Megan Lavengood’s methodology (2020), though her binaries, geared toward ’80s synthesizer timbres, are based on spectral characteristics rather than physiological aspects of vocal delivery (see also Hatten 1994, Chapter 2, for more on musical markedness). Reducing these four vocal parameters to binaries is a simplification, as most of them are more of a continuum than a simple on/off switch. For instance, breathiness arises from excessive airflow across the vibrating vocal folds, and can thus occur in varying degrees, with no identifiable point at which a vocal utterance would switch from “neutral” to “breathy.”(10) Finally, it is important that I note that this small set of binaries does not nearly capture all the nuances of vocal delivery; I chose these four simply because they are the parameters that Morissette most saliently manipulates across Jagged Little Pill.
[3.4] This article’s Appendix contains the album’s complete lyrics with color-coded highlighting to indicate when Morissette uses each of these six vocal styles. I use this same color coding in analytical examples throughout this article. (The color coding also indicates Morissette’s vocal effects, such as vocal fry, which I discuss at the end of this section.) Analyzing vocal style is of course highly subjective, and I doubt that any reader will agree with my analysis all of the time; indeed, I myself often wonder what I was thinking when I listen through my analysis on a different day. Nevertheless, the Appendix provides a good way to get these vocal styles in one’s ears and gives an album-level picture of how Morissette uses her vocal palette. As I turn to detailed discussion of each vocal style, I encourage readers to use the Appendix as a supplement to the examples below.
Speech-song
Example 4. Speech-song in first verse–prechorus–chorus cycle of “All I Really Want” (track 1)

(click to enlarge and listen)
Example 5. Medley of other speech-song examples from across Jagged Little Pill

(click to enlarge and listen)
[3.5] Morissette’s speech-song, so named because it projects a kind of easy speech-like delivery, is the most common style on Jagged Little Pill, and it seems to act as Morissette’s default mode of delivery. Morissette introduces her speech-song right away on the album, as she delivers the majority of the first track “All I Really Want” in this style. Example 4 demonstrates speech-song in this song’s first verse–prechorus–chorus cycle, and Example 5 gives a few more examples of speech-song from elsewhere on the album. As we saw in Example 3, Morissette’s speech-song sits comfortably in her mid-range chest voice with neutral, non-breathy phonation. The most salient sonic characteristic of Morissette’s speech-song is her use of twang, specifically what Estill voice training calls “nasal twang” (see Heidemann 2016, [3.17]). Physiologically, this type of twang comes from a constricted pharynx—a tight throat—and a mostly open velum, or soft palate, so that air flows out through both the mouth and nose. (You can especially hear the twang on the line “how appropriate” from Example 4.) The term “twang” carries strong associations with country music, as Jocelyn Neal has discussed at length (2018), but its vocal tract setup is common across genres and doesn’t necessarily signify a country style in the absence of Southern-accented diction. Heidemann points out that Chaka Khan, Aretha Franklin, and Robert Plant regularly exhibit twang in their singing, and a twangy setup is characteristic of many of Morissette’s alt-rock contemporaries, such as the Smashing Pumpkins’ Billy Corgan and Oasis’s Liam Gallagher.
Example 6. Standard spectrogram of Morissette’s speech-song on the line “did you think about your bills” from the third verse of “All I Really Want” (track 1, at 3:09)
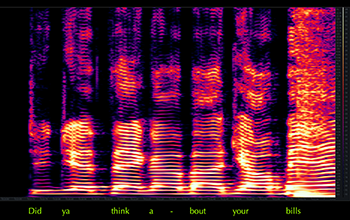
(click to enlarge and listen)
Example 7. Spectrum graph showing frequency amplitudes (averaged across “did ya think about your” from Example 5, all sung on
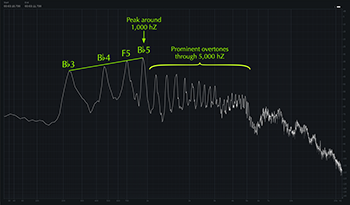
(click to enlarge and listen)
[3.6] Some writers have noticed that by shrinking the pharynx, nasal twang amplifies the voice’s higher overtones (Malawey 2020, 119; Chandler 2014, 40). Louder higher overtones result in a perceptually “brighter” vocal sound and also increase the voice’s ability to project amid competing sounds, which allows Morissette to stick to a relaxed, nonchalant delivery without struggling to be heard.(11) We can observe the overtone profile of Morissette’s speech-song through spectral analysis. Examples 6 and 7 focus on a brief moment in the third verse of “All I Really Want” where Morissette’s voice is alone in the texture, on the lyric “did ya think about your
[3.7] What I’m calling speech-song is probably what Fournier had in mind when she described Morissette’s vocal aesthetic on Jagged Little Pill as “notable variously for its staccato delivery, its hard consonants, [and] its mimicry of speech” (2015, 48). Fournier interprets this aesthetic as “challeng[ing] conventions about the ‘proper’ use of the female voice” (42), and indeed Morissette’s mid-range, twangy speech-song presents a stark contrast with the sound of contemporaneous pop singers like Madonna, Celine Dion, and Mariah Carey. This type of twang is also a decidedly untrained sound, one unacceptable in classical singing traditions. (That said, vocal twang is rarely accidental in pop singers; as Jocelyn Neal puts it, “singers often go to great lengths to sound as if they haven’t gone to any lengths at all” [2018, 51].) Overall, then, Morissette’s speech-song presents her album persona as both authentic and relatable—and in particular banishes any hint of her prior incarnation as the mononymous Alanis, manufactured Canadian teen idol.(13)
Modal voice
Example 8. Modal voice in “Head Over Feet” (track 4, second verse and chorus, 1:00–1:42)

(click to enlarge and listen)
[3.8] Although I referred to speech-song as Morissette’s default style, it is not entirely unmarked. As shown in the top row of Example 3, speech-song has one marked timbral feature, namely twang, as we have seen. When Morissette turns off the twang while remaining in her neutral, mid-range chest voice, the result is what I call her “modal voice.”(14) Morissette’s modal voice is, timbrally speaking, completely unmarked—it is just her cleanest, most unaffected way of singing. Perhaps not surprisingly, she does not use her modal voice all that much on Jagged Little Pill, since it essentially removes much of her voice’s expressive significance. The highest concentration of modal voice on the album comes in the song “Head Over Feet.” I mentioned above that this song’s lyrical theme of devotion and infatuation is somewhat anomalous on the album, and her reliance on modal voice in this song when it is rare elsewhere further sets this song apart from the album’s other tracks. Example 8 gives highlighted lyrics and audio for the second verse–chorus cycle, which is delivered nearly entirely in Morissette’s modal voice. To me, Morissette’s clear, unmarked modal voice projects an air of deep sincerity; there’s no sass or cocky veneer, just Morissette’s real, sincere thoughts (or at least those we ascribe to her inhabited persona). The lyrics to “Head Over Feet” are an almost corny pledge of devotion to a romantic partner, and given its placement amid furious breakup anthems and toxic relationship stories, we might be tempted to read some sarcasm or—dare I say—irony in this song if she had not sung it with such a pure, unadorned vocal delivery.
Belt
Example 9. Belt voice in the choruses of “Forgiven” (track 6) and “You Oughta Know” (track 2)

(click to enlarge and listen)
[3.9] When Morissette climbs into her high register while holding her vocal folds in chest voice, we hear the phenomenon known as belting. Generally, belting signifies the use of chest voice in a pitch register where head voice would be possible and probably much easier. Morissette belts a lot on Jagged Little Pill, especially in chorus sections; Example 9 gives the choruses from “Forgiven” and “You Oughta Know,” both of which are entirely belted. As these two passages demonstrate, Morissette leans especially into her belt voice when expressing anger, whether at the hypocrisy and sexism of the Catholic church in “Forgiven” or at her selfish ex-boyfriend in “You Oughta Know.”
Example 10. Spectrum graph of belted

(click to enlarge and listen)
Example 11. Spectrum graph of belted B4 on “cryin’” from “why are you cryin’?” in “Perfect” (track 3, at 2:18)
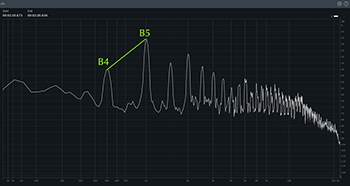
(click to enlarge and listen)
[3.10] As indicated in Example 3, Morissette’s belt voice involves two marked timbral features, namely twang and high register. As Kate Heidemann has explained, belting is generally achieved with some degree of nasal twang (2016, [3.17]), but because of the high register it doesn’t sound as twangy as speech-song. We might be able to see why in its spectral qualities. Recall that Example 7’s spectrum of a
[3.11] Using chest voice in one’s higher register requires significant airflow and muscular support, especially in the lower abdomen, and usually results in a loud sound similar to yelling or shouting (see Malawey 2020, 45, and Chandler 2014, 39). Many commentators highlight the physicality of belting; Barb Jungr, discussing belting in the context of gospel singing, describes it as “a full-throttle sound and is very evident when singers seem on the edge of their voice and emotion: one can almost hear the physical effort employed to make the sound, and it is a quality that would have been very valuable before amplification as it enables high-powered sound to be made and heard over other instruments” (Jungr 2002, 107; see also Heidemann 2016, [3.27]). Indeed, the spectra in Examples 10 and 11 show that Morissette’s belt has consistently loud overtones all the way up past 10,000 Hz, which is consistent with what other studies of belting have shown (Feld et al. 2004, 335; see also Heidemann 2016, [3.17], and Malawey 2020, 45). Belting thus projects strength and power, both in the singer’s physical body and in the voice’s sonic characteristics.
Soft voice, sweet voice, and squeal
[3.12] The three styles we have looked at so far—speech-song, modal voice, and belt—all share two unmarked characteristics: chest voice and neutral phonation. These two domains are, to me, the most perceptually salient out of the four timbral binaries i n Example 3. So, despite their differences in twanginess and/or pitch range, these three vocal styles are overall somewhat similar. The three remaining vocal styles listed in Example 3, which I call “soft voice,” “sweet voice,” and “squeal,” all involve either head voice or breathy phonation (or both). Breathiness and head voice both project some measure of quietness, as both create less extreme fluctuations in air pressure than their unmarked counterparts.(15) Notably, breathiness and head voice are both often associated with femininity, and breathiness in particular is associated with various types of intimacy (see Malawey 2020, 46–50 and 109–10; Heidemann 2016, [3.6]; and Hamm 2018). On Jagged Little Pill, these vocal styles are frequently recorded with close miking, given few if any overt production effects, and set to a minimal and/or distant accompaniment, all of which contributes to an overall sense of physical closeness, representing what Allan Moore refers to as the “intimate proxemic zone” (Moore 2012, 184–88). To Fournier, Morissette’s use of head voice represents “helplessness,” which is set in opposition to “the quest to be in control” represented by chest voice (Fournier 2015, 49).
Example 12. Soft voice and sweet voice in the intro and first verse of “Ironic” (track 10, at 0:00)

(click to enlarge and listen)
[3.13] “Ironic” opens with a bit of ad-libbing in Morissette’s sweet voice, followed by a verse mostly in her soft voice, as shown in Example 12. Sweet voice combines Morissette’s high-register head voice with breathy phonation, which you can hear in the first eight seconds of the example. Soft voice refers to Morissette’s use of breathy phonation in her mid-range chest voice, which you can hear beginning eleven seconds into the example. Morissette often juxtaposes sweet voice and soft voice like this, as sweet voice is essentially the high-register version of soft voice (much like how belting is the high-register version of speech-song), as we will see in the analysis of “Perfect” below. Note how these two voices in “Ironic” are recorded “dry” with close miking and sparse accompaniment, as if we are listening to Morissette whispering in our ear.
Example 13. Spectrogram of the isolated vocal line from the opening of “Ironic”
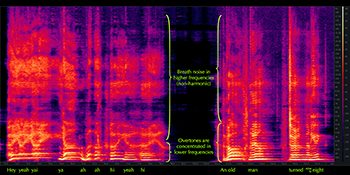
(click to enlarge and listen)
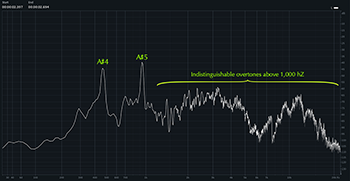
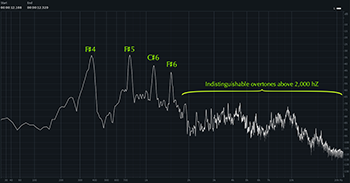
[3.14] Breathiness and head voice produce similar effects on the voice’s spectral arrangement, namely much less activity in the higher overtones and a comparatively louder fundamental frequency (Malawey 2020, 109). In Example 13, I have isolated the opening vocal line from “Ironic” using the music rebalance feature in Izotope’s RX software and displayed the resulting spectrogram. As the spectrogram shows, pitch activity is concentrated on the fundamental and first few overtones, especially when Morissette sings in head voice, represented by the yellow lines concentrated at the bottom of the spectrogram. Higher frequencies are present, but here they do not arise from overtones of the sung pitch, instead coming from non-pitched breath noise, represented by the cloudy activity near the top of the spectrogram. Examples 14 and 15 show spectrum graphs of moments in both sweet voice (Example 14) and soft voice (Example 15); in the former, we see spikes on the fundamental and first overtone, but then just noise above that, and in the latter, there are a few more visually perceptible overtones, but they quickly disappear above around 2000 Hz. Compare these to the spectra in Examples 7, 10, and 11 showing speech-song and belt, where overtone spikes were visible in much higher frequencies.(16)
Example 14. Spectrum graph of sweet voice on
(click to enlarge and listen) | Example 15. Spectrum graph of soft voice on
(click to enlarge and listen) |
Example 16. Squeal in the prechorus of “All I Really Want” (track 1, at 0:42)

(click to enlarge and listen)
Example 17. Spectrum graph of squeal on the syllable “-fore” from “before the gunshot has gone off” (“All I Really Want,” track 1, at 0:44)

(click to enlarge and listen)
[3.15] Finally, we get to Morissette’s least-used vocal style, which I call “squeal.” The word “squeal” is not generally used as a compliment, and indeed this vocal style seems intended to sound painful and evoke some grimacing. I identify only two places on the album where Morissette uses this style: the bridge of “Perfect,” discussed in my analysis below, and briefly in the prechoruses of “All I Really Want,” the first of which is given in Example 16. In this prechorus’s two moments of squeal—on “-fore the gunshot” and “the floor if I wasn’t”—Morissette breaks from her twangy speech-song into head voice as the melody climbs up to D5. Rather than open her pharynx to remove the twang and relax her vocal folds into breathy phonation, as in sweet voice, Morissette holds both tight, resulting in a pinched sound. In terms of our four binaries, squeal involves three marked values—head voice, constricted vocal tract, and high register—and one unmarked value—neutral phonation—as shown in Example 3. It is a bit hard to generalize about the spectral characteristics of Morissette’s squeal, as she uses it so rarely and never without thick accompaniment. Nevertheless, the analysis is consistent with what we would expect from a combination of twang and head voice: the twang boosts the higher overtones in relation to sweet voice, but the head voice dampens the higher overtones in relation to speech-song or belt, so the result falls between Examples 10–11 and Examples 14–15. Example 17 demonstrates with a spectrum graph of the syllable “-fore” from “before the gunshot” in the prechorus of “All I Really Want,” with the vocal line again isolated using Izotope’s music rebalance feature.
Vocal effects: yodel breaks, vocal fry, and production effects
Example 18. Some examples of prominent yodel breaks from across Jagged Little Pill

(click to enlarge and listen)
[3.16] One cannot discuss Alanis Morissette’s voice without mentioning her hallmark vocal effect, which I call her “yodel break.” The yodel break is not really a vocal style, and thus isn’t listed in Example 3, but is instead a paralinguistic utterance that Morissette frequently places at the ends of phrases.(17) Her yodel breaks involve a sudden shift from chest voice to head voice on a neutral vowel, producing an effect that sounds like a cross between yodeling, sighing, and crying. Example 18 gives several examples of Morissette’s yodel break (in the annotated lyrics the breaks are indicated by a superscripted “h,” highlighted in yellow). Morissette’s yodel break is all over Jagged Little Pill (scan through the Appendix to see), and it is a striking effect that is rare in popular songs. (The yodel break is also a hallmark sound of Dolores O’Riordan, lead singer for the Cranberries, a band with documented influence on Morissette’s style [see Gordon 2015]; listen to their song “Zombie” at around 1:42 for an example.) Morissette’s yodel breaks sound like bottled-up air bursting out of her vocal tract, giving the impression of an unintentional outpouring of raw emotion. Patrick Dailley interprets such yodel breaks to suggest “a kind of instability within the personae of the singers,” due to the rapid flip “between the voice of control [i.e., chest voice] and the voice of vulnerability [i.e., head voice]” (quoted in Lacasse 2010, 241). Morissette’s yodel breaks, in other words, might represent the sonic signature of her album persona: she is full of emotion and no amount of effort can prevent those emotions from surfacing.(18)
[3.17] Vocal fry, or creaky voice, is generally considered a vocal register akin to chest voice or head voice,(19) but on Jagged Little Pill Morissette uses it more as a brief vocal effect than a sustained register. Physiologically, vocal fry results from such low tension in the vocal cords that they flap around irregularly, resulting in less perceptible pitch along with audible popping and rattling; this phenomenon can be directly observed by means of a laryngoscope. Critics love to cite vocal fry, usually disparagingly, as a hallmark of millennial women’s speech, though it is not at all limited to women or millennials (see Colapinto 2021, 155–58; Pecknold 2016, n. 4; and Wallmark 2022b, [30–40]). Vocal fry in pop singing peaked when Britney Spears ascended the charts in the late 1990s; producer Max Martin would even highlight Spears’s fry by mixing it with a synthesized percussion scrape (see Zagorski-Thomas 2014, 49). Predating all of this, Morissette uses vocal fry mostly as a soft, nonchalant way into a phrase, as we have already encountered in “Not the Doctor” (first excerpt in Example 5), “Head Over Feet” (Example 8), and “Ironic” (Example 12) (look for dark-blue highlighting over white text in these examples, and also throughout the Appendix).(20) In such contexts, vocal fry seems like an extension of Morissette’s speech-song aesthetic (even when it is not used in conjunction with speech-song), as it is pretty much the antithesis of polished, trained singing.
Example 19. “You Oughta Know,” prechorus (track 2, 0:36): manual double tracking, with each of the two recorded tracks panned hard to one side

(click to enlarge and listen)
Example 20. “Ironic,” bridge (track 10, 1:52): flanging effect

(click to enlarge and listen)
[3.18] Finally, Morissette occasionally subjects her voice to perceptible studio manipulations. There are always some studio effects present, including reverb and compression, but here I’m referring to effects that produce a “wet” sound—one that doesn’t sound natural (see Malawey 2020, 127–30, on the wet/dry binary.) As producer Glen Ballard stated in the quote in [3.1] above, most of the time Morissette’s voice is presented as “dryly” as possible. So when a “wet” production effect does surface, it is fairly noticeable. There are two salient production effects present on Jagged Little Pill. The first is manual double tracking, produced by recording the vocal line twice and playing both simultaneously, and the second is flanging, a type of artificial double-tracking in which the original signal is repeated at a very short delay, creating an alien-like swooshing effect. An example of the former comes in the prechorus of “You Oughta Know,” given in Example 19, where each of Morissette’s two recorded vocal tracks is panned hard to one side, creating a sort of split-screen audio effect. An example of the latter comes in the bridge of “Ironic,” shown in Example 20, which album engineer Chris Fogel has cited as an attempt at “a little bit edgier, not so polished sound” (Gordon 2015).
Analytical Interlude: “Perfect”
Example 21. “Perfect” (track 3), annotated lyrics

(click to enlarge and listen)
[4.1] In the next section below, I will make the case that Morissette’s various vocal styles play an important structural role across Jagged Little Pill. Before doing so, though, I’d like to take a closer look at how she deploys her vocal palette across a single song by considering the album’s third track, “Perfect.” This song’s lyrics explore the psychological effects of excessive parental pressure, told through the first-person perspective of the toxic parent. The highlighted lyrics are given in Example 21, along with audio of the first two verse–chorus cycles. Despite the first-person setting, we are unlikely to equate this song’s parent character with Morissette’s album persona (not least because the latter is 21 years old). Lines such as “if you’re flawless, then you’ll win my love” and “I’ll live through you” show a bit more self-awareness than one would expect from an overbearing parent, and we are more likely to understand Morissette’s persona as a commentator on her own childhood experiences of toxic parenting, using the first person to demonstrate the underlying message that comes across from this parenting style rather than any actual words the parent might use. (Indeed, in the Broadway adaptation of Jagged Little Pill, the character who sings the song is not the mother MJ but her son Nick.) That is, persona and protagonist are not the same in this song. As I mentioned earlier, when persona and protagonist are different, we can understand the lyrics to be enclosed in implied quotation marks, and even though we ostensibly hear the protagonist’s words, it is Morissette’s persona who controls the narrative.
[4.2] So what is Morissette telling us through this parent-protagonist’s words? Reading into the lyrical shift from “be a good boy” to “be a good girl” in the first and second choruses—as well as the fact that the real-life Morissette has two brothers—Fournier interprets the song’s lyrics as “an interesting take on the gendering of ‘perfection’,” wherein boys are gently nudged to “measure up” to their potential, but girls are scolded for “screw[ing] it up” and told to “keep quiet” (Fournier 2015, 54). By acting out a parent’s different attitudes toward their sons and daughters, Morissette offers cutting commentary both on her own upbringing and more generally on parents’ roles in perpetuating problematic gender roles across society. The lyrics of the first two verse–chorus cycles certainly communicate these gendered attitudes to some degree, but what really lays bare the differences is Morissette’s vocal delivery. As Example 21 shows, Morissette sings the song’s first verse and chorus using her soft voice—the breathy, chest voice indicated by gray highlighting—with a handful of nearly imperceptible shifts into head voice, producing sweet voice (in yellow). But in the second cycle—when the accompanimental texture shifts from guitars and shakers to a full band—Morissette gives us her twangy speech-song, moving into belt as the melody climbs into her higher range.
[4.3] Through these contrasting vocal styles, Morissette’s parent-protagonist communicates submissiveness toward their son and dominance over their daughter. As discussed above, the main spectral difference between soft/sweet voice and speech-song/belt is in the amplitudes of higher overtones relative to the fundamental: specifically, they are much quieter in the former than in the latter. Louder higher overtones allow the voice to carry over dense sonic environments (often referred to as a “big” voice), whereas vocal sound concentrated at the fundamental and lower overtones risks being swallowed up by competing sounds (suggesting a “small” voice). Combining this size metaphor with the gendered split across the two cycles, Morissette shows the parent-protagonist making themselves small with their boy and big with their girl—and, by comparison, making the boy feel big and the girl feel small.
Example 22. Spectrum graph of sweet voice on
(click to enlarge and listen)
Example 23. Spectrum graph of belted
(click to enlarge and listen)
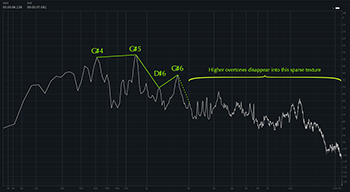
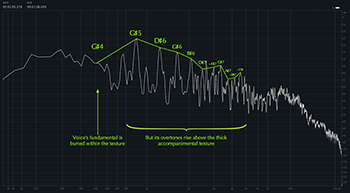
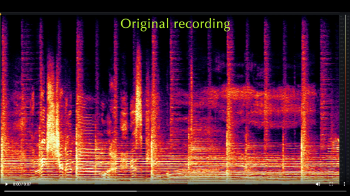
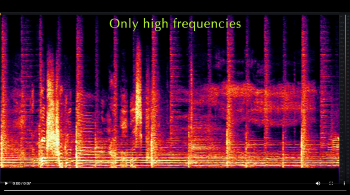
[4.4] To show this specifically in “Perfect,” Examples 22 and 23 juxtapose equivalent moments in the first and second verses: Example 22 shows the syllable “-nough” from the song’s opening line “Sometimes is never quite enough,” which is sung in sweet voice, and Example 23 shows the syllable “up” from the second verse’s opening line “How long before you screw it up?,” which is belted. (Note that I did not isolate the vocal line for these examples, so the spectra analyze the full texture.) The former shows a pronounced dropoff after the fundamental and first overtone, to the point where the higher overtones barely peek out of the overall sonic texture; the latter, on the other hand, shows overtones far louder than the accompaniment’s sounds through the highest frequencies—even though this verse features a much more active accompanimental texture. The spectral saturation in Example 23 visually demonstrates the parent’s expression of sonic dominance in the second, daughter-facing cycle. But when the parent directs the “good girl” to “keep quiet,” Morissette demonstrates by falling into sweet voice, abruptly quieting the voice’s higher frequencies. Listen to Video Examples 1 and 2, which play the line first in its original form (Video Example 1) and then with only frequencies above 2 kHz, which is around C7 (Video Example 2). In the latter, you can hear the voice virtually disappear from that higher frequency range on the line “keep quiet.” This is Morissette making her voice small.
Video Example 1. Spectrogram of “the least you can do is keep quiet,” with “keep quiet” sung in sweet voice
(click to watch video) | Video Example 2. “The least you can do is keep quiet” with frequencies below 2 kHz removed
(click to watch video) |
Example 24. Squeal and belt in the bridge of “Perfect” (track 3, at 1:59)

(click to enlarge and listen)
[4.5] In the song’s bridge, also the narrative climax, the parent-protagonist turns toward introspection, reflecting on their own psychological baggage underlying their need to control their children (see Example 24). The line “compared to him, compared to her” highlights that the different gendered attitudes come from the same internal struggle and ultimately have a similarly detrimental effect on both sons and daughters. Morissette delivers this bridge somewhere between squeal and belt. Though squeal and belt have quite different effects, the only distinction in vocal delivery is head versus chest voice, and Morissette hovers in between those two vocal registers, producing what many vocalists call “mixed” voice (see Malawey 2020, 50). For example, the section’s final line—“what’s the problem, why are you crying?”—sounds more like a full-throttle belt, while the words “never” in the first line and “own” in the fourth sound like pure squeals; the rest combines elements of both. Regardless, the section’s overall pinched quality removes much of the strength and power associated with belt voice, instead producing a cutting sense of tension, as if this tortured parent is forcing air through their vocal tract to pretend at control when in reality they are internally unhinged.
[4.6] After the bridge, we return to the texture, delivery, and lyrical vibe of the first cycle, here with just a final chorus—again addressed to a “good boy”—plus a heartbreaking final line (“We’ll love you just the way you are—if you’re perfect.”). After we’ve heard the second cycle’s aggressiveness and the bridge’s psychological reveal, we understand that this final chorus’s gentleness is just as toxic as anything else. In this way, the final chorus recasts the first cycle’s message in a darker light: what may have seemed like harmless parental encouragement is now shown to be deeply damaging, not only to the “good boy” who receives it but also to the girls who see themselves treated differently and to gender dynamics in society writ large.
Structure
[5.1] The discussion of “Perfect” demonstrates the expressive potential of Morissette’s vocal palette. Shifts in vocal style add a sonic and corporeal element to a song’s lyrical message, which in this case supports the idea that parental pressure to be perfect is both gendered and reflective of personal psychological baggage. But the analysis also demonstrates how closely synchronized Morissette’s vocal styles are with the song’s formal sections. In “Perfect,” we have one lyrical idea in the first verse–chorus cycle (soft pressure on boys), matched with soft and sweet voice, followed by a complementary idea in the second verse–chorus cycle (aggressive pressure on girls), matched mostly with speech-song. The bridge then gives us a contrasting perspective (self-reflection), matched with squeal and belt, and the final chorus returns to the lyrical idea and vocal delivery of the first cycle, which now carries a deeper meaning after we’ve heard all that contrasting material. Put another way, Morissette’s vocal delivery is not only an expressive feature but also a fundamentally structural aspect of this song.
Example 25. Close synchronization of vocal style and formal structure in “You Oughta Know” (track 2): four vocal styles across four sections/subsections

(click to enlarge and listen)
[5.2] Vocal styles synchronize with formal divisions across Jagged Little Pill. Scrolling through this article’s Appendix, we can see that most formal sections are delivered in a single vocal style (with other styles sometimes ornamenting individual words or phrases), and that most songs shift vocal styles from one section to another. “You Oughta Know” exemplifies both trends, as shown in Example 25: here, we essentially get four vocal styles lining up with four eight-measure passages (including a two-part verse, plus prechorus and chorus). The prechorus here involves some studio effects—specifically, Morissette’s voice is double-tracked, with each track panned to one side of the stereo mix—which arrive within a gradual intensification from Morissette’s soft voice at the start of the verse to belt in the chorus.(21) Correlation between vocal delivery and formal sections is not particularly surprising, especially in this mid-’90s alt-rock context, where terraced timbral shifts from section to section are common. The point I want to make, though, is that these section-linked vocal shifts do not just passively reinforce an existing musical structure, but rather they create structural relationships affecting our perception of a song’s form.
Example 26. “Right Through You” (track 5): similar to “You Oughta Know,” a progression from soft voice to belt across a verse–chorus cycle

(click to enlarge and listen)
Example 27. “Not the Doctor” (track 11): another belted chorus, this time after speech-song in the verse

(click to enlarge and listen)
[5.3] To see what I mean, consider the similarities among “You Oughta Know,” shown above, “Right Through You,” shown in Example 26, and “Not the Doctor,” shown in Example 27. In all three songs, Morissette builds up to a belted chorus from a more softly delivered verse: “You Oughta Know” and “Right Through You” begin in soft voice, while “Not the Doctor” starts in speech-song. Lyrically, all three songs fall under the category of “gendered anger,” as shown earlier in Example 2. More specifically, they all deal in some way with Morissette’s persona refusing to be submissive to problematic men. In “You Oughta Know,” Morissette pushes back against her ex’s sexual power over her, remaining defiant in the face of romantic injustice. In “Right Through You,” she calls out music-industry sexism, belting that she sees/knows/feels/walks “right through” an executive who “took a long hard look at my ass and then played golf for a while.”(22) And in “Not the Doctor,” Morissette rejects a feminized caregiving role in a romantic relationship, where she would constantly be serving her partner’s needs at the expense of her own identity. All three songs can be read to embody the feminist tenet of the personal being political; each personal story Morissette recounts symbolizes a broader social problem, whether the “master plot of male sexual power” (Burns 2010, 184), sexual harassment and intimidation in the record industry, or the expectation of female subservience in heterosexual couples.
[5.4] We can understand these songs’ forms to be organized around this narrative of feminist resistance. The songs’ progressions from verse to chorus show a gradual change from subordination to strength. In “Right Through You,” for instance, the first verse tells how the unnamed executive brushed Morissette off; the first four-bar phrase recounts what happened, delivered somewhat meekly in Morissette’s soft voice, while the second four-bar phrase describes how the executive made Morissette feel, now delivered a bit more confidently in speech-song (though Morissette still deferentially calls him “sir”). The chorus, now belted, delivers the song’s scathing message of dominance—no matter how patronizing this man is, Morissette knows all along that she’s the one with the real power. Note that the verse’s lines all have “you” as the grammatical subject (“you mispronounced,” “you didn’t wait,” etc.), but in the chorus “I” takes over the grammatical agency (“I see,” “I know,” etc.). The chorus, in other words, represents a rejection of the verse: the strong and powerful belt voice sonically dominates in a way that soft voice and speech-song cannot, and the lyrical message flips the gendered power dynamic to place Morissette in the dominant position.
[5.5] “You Oughta Know” and “Not the Doctor” exhibit similar formal progressions. In the former, as mentioned, the cycle’s four eight-measure passages line up with soft voice, speech-song, processed speech-song, and belt. Alongside this progression, the lyrics begin hesitantly (“I’m happy for you,” etc.) but quickly grow more hostile; as Lori Burns describes it, the verse begins “timidly at first but then [exhibits] greater disdain and aggression; in the prechorus she reflects on the betrayal of that relationship
Example 28. “All I Really Want” (track 1): speech-song governs verse, prechorus, and chorus

(click to enlarge and listen)
Example 29. “Hand in my Pocket” (track 4): similar

(click to enlarge and listen)
Example 30. “You Learn” (track 7): similar, with modal voice in prechorus

(click to enlarge and listen)
[5.6] Now let’s look at another group of three songs: “All I Really Want,” “Hand in My Pocket,” and “You Learn” (Examples 28, 29, and 30). In these three songs, Morissette delivers both the verses and the choruses mostly in speech-song (“You Learn” also adds a prechorus in modal voice). Though the surrounding sonic environment changes from section to section, Morissette herself stays grounded in her relaxed, twangy default style. These three songs fall under the “self-description” category in Example 2, where Morissette expresses her personal philosophies and desires: in “All I Really Want,” Morissette tells us what she looking for in a partner and in life; in “Hand in My Pocket,” she explains her outlook of accepting herself despite what life throws at her; and in “You Learn,” she advises welcoming hard times so as to gain valuable life skills. By delivering these choruses in the same relaxed speech-song as the verses, Morissette presents the chorus as confirmation or support of the verses. The verses of “Hand in My Pocket,” for instance, list various contradictions, which Fournier describes as “some of the many downsides of youth (being broke, being green, being lost) as they might be weighed against some of its upsides (being happy, being wise, being hopeful)” (2015, 54). In the chorus, Morissette reassures us that “everything’s gonna be fine, fine fine,” conveying the idea that the verses’ contradictions are not problems to be overcome but rather parts of life to be embraced. In “All I Really Want,” the verses and prechoruses find Morissette wondering if her personal quirks are turning off potential partners (“Do I stress you out?,” etc.), but in the choruses, she doubles down on her idiosyncratic personality—and its attendant speech-song—by suggesting that the problem is with her partners, not with herself (“And what I wouldn’t give to find a soulmate: someone else to catch this drift,” etc.). And in “You Learn,” whose lyrics provide the album’s title, Morissette’s chorus explains why, in the verses and prechoruses, she recommended seemingly painful experiences (jagged little pills to be swallowed down). Unlike the verses’ stories in “You Oughta Know,” “Right Through You,” and “Not the Doctor”—where problematic gender roles needed to be rejected with strong and powerful belt voice—the potentially negative verse stories in “All I Really Want,” “Hand in My Pocket,” and “You Learn” are taken in stride, treated as positive forces in regular life through Morissette’s cool, comfortable speech-song.
[5.7] Granted, all six of these songs can be analyzed to be “in verse–chorus form,” insofar as their thematic grouping suggests verse sections and chorus sections, with or without an intervening prechorus. But such container-based labeling is really only the first step in formal analysis. To me, a song whose chorus rejects the mood of its verse (as in Examples 25–27) has quite a different effect from one where the chorus confirms the verses’ ideas (as in Examples 28–30). And that difference is fundamentally structural—just as formally relevant as, say, whether the verse and chorus share the same chord progression (as in John Covach’s distinction between “simple” and “contrasting” verse–chorus forms [2005]) or whether the chorus begins on or off tonic (as in my own distinction between “sectional” and “continuous” verse–chorus forms [Nobile 2020, 148–98]). The larger point is that musical structure, especially in popular styles, is not restricted to the interplay among so-called “primary parameters”—notes, chords, rhythms, etc.—but also engages the “secondary parameters” of timbre, embodiment, text, etc.(23) Considering voice as a structural element challenges the idea that there is an ontological separation between sound and structure, an idea famously described by Rose Subotnik (1996, 148–76) and explored in depth in a 2004 collection titled Beyond Structural Listening (Dell’Antonio 2004). Put another way, music theory’s recent timbral turn, so to speak, does not necessarily represent a rejection of structural analysis, but rather it can invite expanding our concept of musical structure to acknowledge the interconnection of sound and structure, especially in popular music contexts.
Conclusion
[6.1] It is not a stretch to speculate that Jagged Little Pill’s enduring appeal over a quarter-century after its release is in large part due to Morissette’s unique way of singing. Rachel Syme, writing in 2019 as the Jagged Little Pill musical prepared to hit Broadway, explains Morissette’s vocal legacy thus:
Morissette remains, to this day, one of the only artists who seem to invite singing like her when her songs are on: It is hard to hear “Hand in My Pocket” and not want to affect her singular and strange, almost Alpine voice. You become Morissette because what she is saying is less of a verbal transmission and more of a whole-body release. She gave voice to her own humiliation and abasement, and in re-enacting that, you may feel a bit humiliated yourself, like a teenager slamming a bedroom door. (Syme 2019)
On Jagged Little Pill—the album—we attach ourselves to Morissette’s persona through the sound of her voice: her raw and personal lyrics tell us what she is thinking, and her uninhibited, minimally processed voice shows us how she is feeling. In this article, I have shown how Morissette creates the album’s vocal palette by manipulating certain parameters to create a set of vocal styles, each with its own timbral profile and expressive connotations. As we saw in the analysis of “Perfect,” these styles can support and add new dimensions to a song’s text, through both their sonic features and their physiological implications. However, I have also argued that Morissette’s voice is not only an expressive feature, but can also be understood as a structural element of her songs. That is, her vocal sound and delivery are not external ornaments but central aspects of her songs’ forms.
[6.2] My discussion of Jagged Little Pill brings up two broader points relevant beyond Alanis Morissette in particular. First, it is important to distinguish vocal elements that we perceive to be part of a persona’s identity (who is singing?) and those that we perceive as features of that persona’s expression (what are they saying and how are they feeling?). Many aspects of vocal delivery, whether employed consciously or not, are seen as part of a singer’s vocal essence—Bob Dylan’s vocal swoops, Billie Holiday’s “burned” rasp, Dolly Parton’s “baby voice” twang, etc.(24)—providing information about who the singing persona is. In this article, I have focused instead on those vocal parameters that change from moment to moment and song to song. These malleable parameters are not fixed aspects of a singer’s identity, but rather they supplement the lyrics’ meaning with emotional and physical expression. Different singers manipulate different parameters to different degrees, of course, but it is through this vocal variation that singers can present a dynamic and multifaceted persona. This brings me to my second point, which is that the voice’s structural potential arises from the way a singer changes their vocal expression within a single song. Recognizing voice as a structural feature of popular music directly challenges the notion that a song’s identity is contained solely within its notes, chords, and lyrics. In so doing, this recognition shows how analyzing “the music itself” can also speak to a song’s social and political context. A recorded popular song is built not only from chord progressions, melodic groups, and drumbeats, but also from the words and sounds of a singing persona making an expressive statement. Put another way, Alanis Morissette and other popular singers are not only communicating with their voice, not only emoting with their voice, but are in fact composing with their voice.
Appendix
Appendix: Complete lyrics from Jagged Little Pill highlighted according to vocal style [PDF]
Drew Nobile
University of Oregon
School of Music and Dance
961 E 18th Ave
Eugene, OR 97403
dnobile@uoregon.edu
Works Cited
Abdurraqib, Hanif. 2017. “The Alanis Morissette Album From the ’90s America Needs Now.” The New York Times, June 19. Accessed May 16, 2022. https://www.nytimes.com/2017/06/19/opinion/alanis-morissette-jagged-little-pill-musical.html.
Anderson, Kyle. 2015. “Alanis Morissette’s Jagged Little Pill Oral History.” Entertainment Weekly, October 9. Accessed April 19, 2022. https://ew.com/article/2015/10/09/alanis-morissettes-jagged-little-pill-oral-history/.
Auslander, Philip. 2021. In Concert: Performing Musical Persona. University of Michigan Press. https://doi.org/10.3998/mpub.10182371.
BaileyShea, Matthew L. 2014. “From Me to You: Dynamic Discourse in Popular Music.” Music Theory Online 20 (4). https://doi.org/10.30535/mto.20.4.1.
—————. 2021. Lines and Lyrics: An Introduction to Poetry and Song. Yale University Press. https://doi.org/10.12987/9780300262735.
Brøvig-Hanssen, Ragnhild, and Anne Danielsen. 2016. Digital Signatures: The Impact of Digitization on Popular Music Sound. MIT Press.
Burns, Lori. 2010. “Vocal Authority and Listener Engagement: Musical and Narrative Expressive Strategies in the Songs of Female Pop-Rock Artists, 1993–95.” In Sounding Out Pop: Analytical Essays in Popular Music, ed. Mark Spicer and John Covach, 154–92. University of Michigan Press.
Chandler, Kim. 2014. “Teaching Popular Music Styles.” In Teaching Singing in the 21st Century, ed. Schott D. Harrison and Jessica O’Bryan, 35–51. Springer. https://doi.org/10.1007/978-94-017-8851-9_4.
Colapinto, John. 2021. This is the Voice. Simon & Schuster.
Cone, Edward T. 1974. The Composer’s Voice. University of California Press.
Covach, John. 2005. “Form in Rock Music: A Primer.” In Engaging Music: Essays in Musical Analysis, ed. Deborah Stein, 65–76. Oxford University Press.
Dell’Antonio, Andrew, ed. 2004. Beyond Structural Listening? Postmodern Modes of Hearing. University of California Press. https://doi.org/10.1525/california/9780520237575.001.0001.
Duguay, Michèle. 2022. “Analyzing Vocal Placement in Recorded Virtual Space.” Music Theory Online 28 (4).
Eidsheim, Nina Sun. 2019. The Race of Sound: Listening, Timbre, and Vocality in African American Music. Duke University Press. https://doi.org/10.1215/9781478090359.
Feld, Steven, Aaron A. Fox, Thomas Porcello, and David Samuels. 2004. “Vocal Anthropology: From the Music of Language to the Language of Song.” In A Companion to Linguistic Anthropology, ed. Alessandro Duranti, 321–45. Blackwell. https://doi.org/10.1002/9780470996522.ch14.
Ferrandino, Matthew. 2022. “Sonic Identity, Imitation, and Critical Listening in Popular Music.” SMT-Pod 1.5. Podcast audio, 00:44:09. Accessed May 13, 2022. https://smt-pod.org/episodes/season01/#e1.5.
Fournier, Karen. 2015. The Words and Music of Alanis Morissette. Praeger.
Frith, Simon. 1996. Performing Rites: On the Value of Popular Music. Harvard University Press.
Gordon, Holly. 2015. “You Oughta Know: An Oral History of Alanis Morissette’s Jagged Little Pill.” The World, December 18. Accessed December 13, 2021. https://theworld.org/stories/2015-12-18/you-oughta-know-oral-history-alanis-morissettes-jagged-little-pill.
Hamm, Chelsey. 2018. “Representations of the ‘Female Voice’ in Kesha’s Rainbow.” Paper presented at the annual meeting of the Society for Music Theory, Columbus, OH, November 1.
Hatten, Robert. 1994. Musical Meaning in Beethoven: Markedness, Correlation, and Interpretation. Indiana University Press.
Heidemann, Kate. 2016. “A System for Describing Vocal Timbre in Popular Song.” Music Theory Online 22 (1). https://doi.org/10.30535/mto.22.1.2.
Jungr, Barb. 2002. “Vocal Expression in Blues and Gospel.” In The Cambridge Companion to Blues and Gospel Music, ed. Allan Moore, 102–15. Cambridge University Press. https://doi.org/10.1017/CCOL9780521806350.008.
Klayman, Alison, dir. 2021. Jagged. HBO Documentary Films. Accessed December 10, 2021. https://www.hbo.com/movies/music-box-jagged.
Kreiman, Jody, and Diana Sidtis. 2011. Foundations of Voice Studies. Wiley-Blackwell.
Lacasse, Serge. 2010. “The Phonographic Voice: Paralinguistic Features and Phonographic Staging in Popular Music Singing.” In Recorded Music: Performance, Culture, and Technology, ed. Amanda Bayley, 225–51. Cambridge University Press.
Lavengood, Megan. 2020. “The Cultural Significance of Timbre Analysis: A Case Study in 1980s Pop Music, Texture, and Narrative.” Music Theory Online 26 (3). https://doi.org/10.30535/mto.26.3.3.
Malawey, Victoria. 2020. A Blaze of Light in Every Word: Analyzing the Popular Singing Voice. Oxford University Press. https://doi.org/10.1093/oso/9780190052201.001.0001.
Meyer, Leonard. 1989. Style and Music: Theory, History, and Ideology. University of Chicago Press.
Meyer, Robinson. 2016. “Alanis Morissette Recognizes It’s Not Ironic.” The Atlantic, online, May 9. Accessed December 3, 2021. https://www.theatlantic.com/notes/2016/05/alanis-morissette-recognizes-its-not-ironic/481875/.
Moore, Allan. 2002. “Authenticity as Authentication.” Popular Music 21 (2): 209–23. https://doi.org/10.1017/S0261143002002131.
—————. 2012. Song Means: Analyzing and Interpreting Recorded Popular Song. Ashgate.
Moore, Allan, and Ruth Dockwray. 2010. “Configuring the Sound-Box.” Popular Music 29 (2): 181–97.
Neal, Jocelyn. 2018. “The Twang Factor in Country Music.” In The Relentless Pursuit of Tone, ed. Robert Fink, Melinda Latour, and Zachary Wallmark, 43–64. Oxford University Press. https://doi.org/10.1093/oso/9780199985227.003.0003.
Nobile, Drew. 2020. Form as Harmony in Rock Music. Oxford University Press. https://doi.org/10.1093/oso/9780190948351.001.0001.
—————. 2022. “Teleology in Verse–Prechorus–Chorus Form, 1965–2020.” Music Theory Online 28 (3). https://doi.org/10.1093/oso/9780190948351.003.0008.
Pecknold, Diane. 2016. “‘These Stupid Little Sounds in her Voice’: Valuing and Vilifying the New Girl Voice.” In Voicing Girlhood in Popular Music: Performance, Authority, Authenticity, ed. Allison Adrian and Jacqueline Warwick, 77–98. Routledge.
Poyatos, Fernando. 2002. Nonverbal Communication Across Disciplines, Volume II: Paralanguage, Kinesics, Silence, Personal and Environmental Interaction. John Benjamins Publishing. https://doi.org/10.1075/z.ncad2.
Samples, Mark. 2018. “Timbre and Legal Likeness: The Case of Tom Waits.” In The Relentless Pursuit of Tone, ed. Robert Fink, Melinda Latour, and Zachary Wallmark, 119–40. Oxford University Press.
Schilt, Kristen. 2003. “‘A Little Too Ironic’: The Appropriation and Packaging of Riot Grrrl Politics by Mainstream Female Musicians.” Popular Music and Society 26 (1): 5–16. https://doi.org/10.1080/0300776032000076351.
Schubert, Emery, and Joe Wolfe. 2006. “Does Timbral Brightness Scale with Frequency and Spectral Centroid?” Acta Acustica 92: 820–25.
Spreadborough, Kristal. 2022. “Emotional Tones and Emotional Texts: A New Approach to Analyzing the Voice in Popular Vocal Song.” Music Theory Online 28 (2). https://doi.org/10.30535/mto.28.2.7.
Subotnik, Rose. 1996. Deconstructive Variations: Music and Reason in Western Society. University of Minnesota Press.
Syme, Rachel. 2019. “Alanis Morissette Isn’t Angry Anymore. But ‘Jagged Little Pill’ Rages On.” The New York Times Magazine, November 30. Accessed May 16, 2022. https://www.nytimes.com/2019/11/26/magazine/alanis-morissette-jagged-little-pill-musical.html.
Tagg, Philip. 2012. Music’s Meanings: A Modern Musicology for Non-Musos. The Mass Media Music Scholars’ Press.
Wallmark, Zachary. 2022a. Nothing but Noise: Timbre and Musical Meaning at the Edge. Oxford University Press. https://doi.org/10.1093/oso/9780190495107.001.0001.
—————. 2022b. “Analyzing Vocables in Rap: A Case Study of Megan Thee Stallion.” Music Theory Online 28 (2). https://doi.org/10.30535/mto.28.2.10.
Whiteley, Sheila. 2000. Women and Popular Music: Sexuality, Identity and Subjectivity. Routledge.
Wise, Tim. 2007. “Yodel Species: A Typology of Falsetto Effects in Popular Music Vocal Styles.” Radical Musicology 2. Accessed April 4, 2022. http://www.radical-musicology.org.uk/2007/Wise.htm.
Zagorski-Thomas, Simon. 2014. The Musicology of Record Production. Cambridge University Press. https://doi.org/10.1017/CBO9781139871846.
Footnotes
1. The single “Ironic,” Morissette’s third from the album, sparked hot debate about whether the situations described in its lyrics—including rain on a wedding day, 10,000 spoons when all you need is a knife, etc.—are in fact appropriate examples of irony. The Atlantic’s Robinson Meyer, writing in 2016, sums up the history:
For more than 20 years now, since the release of her hit “Ironic,” [Morissette has] had to hear every pedant, every SNOOT, and every 10th-grade English teacher crow that none of the situations in her song are actually ironic. The eternal question of rain-on-your-wedding-day has spawned two decades of thinkpieces (here’s the Times in 2008, Salon in 2014). “Ironic” even has a section on its Wikipedia page entitled “Linguistic usage disputes.” It’s hard to even talk about the literary device now without hearing someone lament the song. Irony, apparently, was described by Socrates, animated by Shakespeare and O. Henry, and killed by a 1995 radio hit. RIP. (2016)
Return to text
2. My use of “persona,” as well as the triad of performer/persona/protagonist, follows that of Allan Moore (2012, 179–84), who draws heavily on Simon Frith’s earlier discussion of the voice in popular song (1996, 184–87). Other authors use the term differently. Philip Auslander’s “musical persona” refers to an artist’s public performing identity, which he contrasts with their “real” identity as an individual person (Auslander 2021). Auslander’s persona is thus primarily an aspect of Moore’s “performer,” as it “persists across different specific performances” (11). Matthew BaileyShea, who focuses on lyrics, equates persona with the lyrical “I,” thus representing Moore’s “protagonist” (BaileyShea 2014; 2021). I should also note that Moore is not entirely consistent in his use of the term; at times he uses the term more in line with Auslander’s musical persona—as when he discusses David Bowie’s Ziggy Stardust performance persona (181)—but most of his analyses imply that the persona is a construct of an individual song, and can even change within a song, as when he refers to Kate Bush’s multiple “personae” in “There Goes a Tenner” (183–84). See also Tagg 2012, 343–82, and Burns 2010, 160–67, for other relevant discussion, and Cone 1974 for some background concepts in analyzing musical personae.
Return to text
3. My discussion of authenticity lines up with what Allan Moore calls “first-person authenticity,” which he describes as “authenticity of expression” (2002, 211–14). As Moore emphasizes, authenticity is “ascribed, not inscribed” (2002, 210): we listeners decide whether what we’re hearing is authentic or not (and different listeners might make different determinations). Mediation, or its lack, is also a perceptual phenomenon, as opposed to an objective one; discussing technological mediation in particular, Victoria Malawey notes that since all recorded music is electronically mediated, the issue “is not the degree to which processing is actually used in recordings, but rather in how some recordings seem more mediated or modified than others” (2020, 145). Artists and marketing teams of course go to extreme lengths to push listeners toward interpreting their songs as authentic—which, ironically, is a particularly inauthentic move.
Return to text
4. “Ironic” is ostensibly just a list of ironies (or non-ironies, as the case may be), but the appearance of a first-person pronoun at the end of the third verse (“it’s meeting the man of my dreams,” rather than “your dreams”) gives the song a personal element; the bridge’s overall message—that bad things often happen in good times, and vice versa—can therefore be read as a lesson Morissette’s persona has learned the hard way.
Return to text
5. There is also of course a third half, so to speak, coming from such other elements as instrumental timbre, music videos, biographies, etc.
Return to text
6. A note on terminology: this article focuses on “vocal delivery,” otherwise known as “vocal sound,” which, as Victoria Malawey summarizes, encompasses the domains of pitch, prosody, and quality (2020, 7). “Vocal timbre” is more specific, generally referring to the last of these three domains (though the others contribute as well, as Malawey shows). The umbrella term “voice” combines vocal delivery with aspects of persona, lyrics, etc.; see Frith 1996, 183–202.
Return to text
7. I do not discuss spatial aspects of Morissette’s recorded vocal sound much in this article, but several authors have discussed how elements of pitch, timbre, and stereo panning combine to place recorded elements within a sonic “virtual space.” Michèle Duguay’s article in this issue (2022) offers the most robust methodology for analyzing vocal placement, drawing heavily on the concept of the “sound box” developed by Moore and Dockwray (2010). See also Moore 2012, 29–49; Brøvig-Hanssen and Danielsen 2016, 21–41; and Zagorski-Thomas 2014, 76–91.
Return to text
8. Ballard claiming credit for not using Auto-Tune is rather anachronistic, as Antares’s first version of the Auto-Tune software didn’t launch until two years after Jagged Little Pill’s release. But I think Ballard is doing a bit of strategic marketing here, even twenty years later. “Auto-Tune” has become cultural shorthand for studio processes that remove so-called “blemishes” in the unadulterated track—in other words, Auto-Tune stands for inauthenticity. By invoking Auto-Tune, Ballard is putting deliberate distance between Morissette and those artists—artists who (as Ballard would have it) remove their own personalities from their records in favor of generic, mass-marketable sounds.
Return to text
9. Head and chest voice have historically carried gendered implications, especially with head voice signaling femininity (Malawey 2020, 46–50 and 109–10; Heidemann 2016, [3.6]; Hamm 2018). Dailley’s associations of head voice with “helplessness” and chest voice with “control” can be understood as a certain take on this gendered binary. Dailly’s online analysis no longer appears at the URL Fournier cites, and online searches have not yielded any results. Fournier’s full citation, which also appears in Lacasse 2010’s bibliography, is Patrick Dailley, “9. Alanis Morissette: ‘You Oughta Know,’ on Jagged Little Pill,” online. http://www.patrickdailly.f9.co.uk/ALANIS.htm.
Return to text
10. Victoria Malawey describes the continuum of phonation in detail, including discussions of perception and physiology and numerous citations of other relevant literature (Malawey 2020, 101–11). Morissette’s shifts from “neutral” to “breathy” phonation represent only half of the continuum; going in the other direction from neutral leads to “pressed” phonation, resulting in vocal sounds often described as “raspy,” “rough,” or “gravely.” Morissette does not use pressed phonation on Jagged Little Pill, though it is a common technique in mid-’90s alt-rock (Eddie Vedder of Pearl Jam, Gavin Rossdale of Bush, e.g.).
Return to text
11. More specifically, timbral brightness is associated with a sound’s spectral centroid—the average of all the frequencies present in that sound, weighted by amplitude. See Schubert and Wolfe 2006; Lavengood 2020, [1.9]; and Wallmark 2022a, 42.
Return to text
12. Using average amplitudes of each frequency across a short span of time, as opposed to snapshotting a single timepoint, removes some of the potential for idiosyncrasies to mess with the data. For one, different vowel sounds have different spectral profiles (owing to different resonant frequencies in the vocal tract, known as formants), but collapsing several vowel sounds into a single graph, as in Example 6, smooths out these differences.
Return to text
13. Morissette had a moderately successful run as a teen pop star prior to Jagged Little Pill, her success largely limited to the Canadian market, with two albums released on MCA Canada under the artist name Alanis: 1991’s Alanis, her self-titled debut album that spawned a Canadian Top-20 hit in “Too Hot,” and 1992’s Now is the Time, which did not sell well and led MCA not to renew her record contract.
Return to text
14. The word “modal” is used in vocal literature to signify, generally speaking, the most common way of singing (“modal” coming from the statistical concept of “mode,” or the most common value within a group). Many voice scientists, especially those focusing on physiological aspects of vocal production, use the term “modal register” as essentially a synonym for “chest voice” (see Malawey 2020, 41), while others incorporate other features into the term (e.g., Kreiman and Sidtis 2011, 62–64). Here, I use the term “modal voice” to mean an entirely unmarked vocal sound; specifically, chest voice in the middle of one’s pitch range with neutral phonation and an unconstricted vocal tract.
Return to text
15. Head voice is achieved when the vocal folds close only at their border (thus creating a smaller area of closure vertically, parallel to the airflow), and breathiness is achieved when the vocal folds do not close all the way (thus creating incomplete closure horizontally, perpendicular to the airflow). Both actions create less pressure buildup in the air coming up from the lungs than in chest voice/neutral phonation.
Return to text
16. Software that extracts vocal sounds from a fuller texture is, of course, making an algorithmic guess as to which frequencies belong to the vocal sound and which belong to other sounds, with no guarantee that it’s capturing the right ones, or all of the right ones. So Examples 13–15 do not necessarily give an accurate picture of Morissette’s voice’s overtone profile at those moments. That said, the texture here is so thin, with just an acoustic guitar alongside the voice, that the extraction is not as heavy a lift as it might be with a fuller texture. Furthermore, the same general frequency ratios are visible in a spectrum of the full, non-extracted texture—it’s just not as visually clear since the guitar’s upper partials are in there as well. Finally, though it is imperfect, an aural comparison can provide a basic accuracy test; to me, the extracted vocal lines here sound pretty similar to the vocal line from the original recording. which is not always true of extracted vocal lines. See also Duguay 2022 for a discussion of other uses of extracted vocal lines.
Return to text
17. More specifically, a yodel break is what Fernando Poyatos calls an “alternant,” a paralinguistic vocal sound that occurs on its own, rather than in conjunction with verbal language. See Poyatos 2002, Chapter 4. See also Wise 2007 for a broader discussion of yodeling across popular styles.
Return to text
18. One might also consider the yodel break as a sonic “brand,” or an aural logo for what Mark Samples calls an artist’s “brand persona” (Samples 2018). Zachary Wallmark demonstrates how rapper Megan Thee Stallion uses a vocal-fry “æ” syllable as a sonic trademark in this way (Wallmark 2022b), and Morissette’s yodel break might function similarly.
Return to text
19. Vocal scientists often identify four vocal registers based on laryngeal mechanisms, labeled M0 through M3, with M0 being vocal fry, M1 being chest voice, M2 being head voice, and M3 being “whistle tone,” when the vocal folds are so tight as to produce an extremely high pitch (Mariah Carey and Ariana Grande are famous for their whistle tone chops).
Return to text
20. See also Spreadborough 2022, esp. [32] and Example 6 on “creak onsets.”
Return to text
21. See Nobile 2022, [3.6] for a discussion of this song’s form, and Burns 2010, 182–88, for a multimodal narrative analysis.
Return to text
22. According to producer Glen Ballard, he and Morissette wrote this song after a particularly stinging rejection from Atlantic Records; see Anderson 2015.
Return to text
23. The distinction between “primary” and “secondary” parameters originates with Leonard Meyer’s 1989 book Style and Music. To Meyer, primary parameters—melody, harmony, and rhythm—are “syntactic,” in that they “establish explicit functional relationships” and articulate closure (209), while secondary parameters—dynamics, timbre, texture, etc.—are “statistical,” in that they are generally “described in terms of amounts rather than in terms of classlike relationships” (15). Meyer argues for the importance of secondary parameters in theorizing 19th-century European musical style, but claims that the “division of parameters into primary and secondary is governed by the lawlike constraints of human perception and cognition” (16).
Return to text
24. See Ferrandino 2022 (on Bob Dylan); Eidsheim 2019, 155–59 (on Billie Holiday); and Heidemann 2016, [3.16] (on Dolly Parton).
Return to text
Copyright Statement
Copyright © 2022 by the Society for Music Theory. All rights reserved.
[1] Copyrights for individual items published in Music Theory Online (MTO) are held by their authors. Items appearing in MTO may be saved and stored in electronic or paper form, and may be shared among individuals for purposes of scholarly research or discussion, but may not be republished in any form, electronic or print, without prior, written permission from the author(s), and advance notification of the editors of MTO.
[2] Any redistributed form of items published in MTO must include the following information in a form appropriate to the medium in which the items are to appear:
This item appeared in Music Theory Online in Volume 28, Issue 4 in December 2022. It was authored by Drew Nobile (dnobile@uoregon.edu), with whose written permission it is reprinted here.
[3] Libraries may archive issues of MTO in electronic or paper form for public access so long as each issue is stored in its entirety, and no access fee is charged. Exceptions to these requirements must be approved in writing by the editors of MTO, who will act in accordance with the decisions of the Society for Music Theory.
This document and all portions thereof are protected by U.S. and international copyright laws. Material contained herein may be copied and/or distributed for research purposes only.

Prepared by Lauren Irschick, Editorial Assistant
Number of visits:
27247